
Les traceurs sous linux (1/2)

🇫🇷 This article is available in French only, part of our cross-post series from our friends at Li[nux embedded.
L’analyse des performances est essentiel pour tout processus de développement d’une application logicielle.
En plus du débogage, il est nécessaire d’utiliser des pratiques d’instrumentation pour garantir les performances attendues d’une application (ou même d’un noyau). L’instrumentation consiste essentiellement à surveiller et à mesurer les performances, à diagnostiquer les erreurs et à écrire des informations de suivi dans les environnements de développement et de production.
Linux propose des outils d’instrumentation connus sous le nom de traceurs.
Dans cette article, nous aborderons le traceur Ftrace.
Pourquoi un traceur?
Les traceurs sont des outils avancés d’analyse et de tests de performances. Ces derniers ne capturent pas seulement que des appels système ou des paquets, mais peuvent généralement tracer n’importe quelle fonction du noyau ou d’une application.
Les traceurs capturent tous les événements qui se produisent dans le noyau (changements de contexte, défauts de pages, interruptions, …., etc).
De nombreux traceurs existent sous Linux, les plus répandus figurent dans l’image suivante.

Tous ces traceurs nous permettent d’obtenir des données comme la latence de l’ordonnanceur ou de l’écriture sur disque, d’être alerté quand une primitive noyau est exécutée ou même modifier le comportement de cette dernière (changer le contenu des paramètres ou la valeur retournée par la fonction).
Traçage ou Profilage de code?
Ces deux termes sont souvent confondus. Pour comprendre la différence, on peut imaginer un navigateur web qui génère plein d’événements (clique sur un bouton, redimensionnement de la fenêtre, défilement avec la molette, …, etc).
Profilage
Un profileur comptabilise le nombre d’événements durant un intervalle sans se préoccuper du moment de leur émission (pas de sauvegarde du timestamp).
Un exemple serai le suivant (depuis t = 0 à t = 5) :
-
30 événements de type clique sur « bouton gauche souris »
-
15 événements de type appui sur une « touche clavier »
-
10 sur la « touche espace »
-
2 sur la « touche échappe »
-
3 sur la « touche s »
Traçage
Un traceur s’intéresse au moment de l’émission de l’événement :

Remarque : Une trace détaillé permet de reconstituer un rapport du profilage.
Des traceurs et profileurs en action
Pour mieux comprendre les traceurs et les profileurs, une animation est disponible sur ce lien : https://jugurthab.github.io/debug_linux_kernel/linux-tracers-utility.html
Ftrace
Ftrace est l’outil officiel de traçage Linux (créé par Steven Rostedt) depuis le noyau 2.6.27. Il est sans doute le traceur le plus connu.
Vérifier le support Ftrace
Pour pouvoir utiliser Ftrace, le noyau doit être compilé avec :
CONFIG_FUNCTION_TRACER CONFIG_FUNCTION_GRAPH_TRACER CONFIG_STACK_TRACER CONFIG_DYNAMIC_FTRACE
Découvrir le traceur Ftrace
Procédons comme un guide étape par étape pour comprendre le fonctionnement de Ftrace :
-
Obtenir les privilèges d’administrateur : Nous devons avoir les droits d’administrateur pour utiliser Ftrace.
root@beaglebone:~$ sudo su -
Localiser le DebugFs : La plupart du temps, il se trouve dans /sys/kernel/debug. Une fois cela fait, Il faut se positionner sur le répertoire Ftrace.
root@beaglebone:~# cd /sys/kernel/debug/tracingAttention : Si vous êtes redirigé, vous n’êtes pas connecté en tant que root. -
Fichiers et paramètres Ftrace : c’est la partie la plus importante dans la compréhension de Ftrace, il faut configurer plusieurs fichiers pour l’utiliser. Nous pouvons lister les différents fichiers et dossiers qui composent Ftrace (voir l’image ci-dessous).
Le tableau suivant résume la fonction des fichiers fondamentaux qui constituent Ftrace :

Bien utiliser Ftrace
La façon la plus simple d’utiliser Ftrace est démontrée ci dessous :
- Sélectionner un type traceur : il existe plusieurs façons de tracer une application (ou un système), Ftrace supporte plusieurs types de traceurs (les types varient selon les architectures et les systèmes).
- Liste des types de traceurs disponibles dans Ftrace : Ftrace inclut plusieurs traceurs que l’on peut lister comme suit :
- Choisir un type de traceur : Une fois que nous connaissons les types de traceursdisponibles, nous devons en choisir un. Nous allons sélectionner le type « function » comme exemple :
- Vérifiez quel traceur est utilisé : il est préférable de toujours vérifier si nous avions bien sélectionner le bon type de traceur (voir l’image ci-dessous) :
2.** Sauvegarder la trace dans le tampon noyau: Au moment où un **traceur est sélectionné, Ftraceest activé mais il n’a pas encore été autorisé à stocker ce qu’il trace. Nous devons accorder à Ftrace l’accès au tampon comme suit :
Remarque : Ftrace commencera immédiatement à tracer lors de l’émission de la commande ci-dessus.
- Lancer le programme à tracer : Nous pouvons tracer n’importe quel programme, nous allons illustrer avec la commande sleep.
- Arrêter la sauvegarde vers le tampon : une fois que le programme que nous voulons tracer à fini son exécution, nous devons bloquer l’accès au tampon par Ftrace (ce qui arrête l’enregistrement des événements).
- Lire la trace : Il est temps de voir la trace produite par Ftrace (voir l’image ci-dessous).
Remarque : **Le résultat de la trace est obtenu par une lecture du fichier **trace.
- Arrêter Ftrace : Ftrace n’a plus d’accès au tampon noyau (mais il est toujours en exécution), il faut l’arrêter :
Optimiser l’usage de Ftrace
Par défaut, Ftrace capture toutes les fonctions du noyau appelées par tous les processus du système. Nous devons l’ajuster afin de réduire les problèmes de performance et optimiser la taille du rapport de trace qui en résulte.
-
Liste des points de trace possibles supportés par Ftrace : Ftrace ne peut pas capturer toutes les fonctions noyau. Seuls celles à qui les développeurs Linux ont attachés une sonde (appellée un point de trace, tracepoint en anglais) *sont disponibles. Nous pouvons afficher la liste des points de traces (fonctions pouvant être tracé par Ftrace*) comme ceci :
# less available_filter_functions -
Tracer un ensemble de fonctions : Nous pouvons restreindre l’ensemble des fonctions à tracer pour n’obtenir que celles qui nous intéressent en utilisant 2 fichiers dans Ftrace :
-
set_ftrace_filter : Permet de choisir les fonctions à tracer
# echo function1 function2 functionN > set_ftrace_filter -
A titre d’exemple, nous pouvons choisir de suivre la fonction SyS_nanosleep comme indiqué ci-dessous :
- set_ftrace_notrace : Les fonctions définies dans ce fichier ne seront pas tracées. Important : Si une fonction apparaît à la fois dans set_ftrace_filter et dans set_ftrace_notrace, elle ne sera pas tracée car set_ftrace_notrace a une priorité plus élevée.
- Tracer un processus particulier : **Nous pouvons forcer **Ftrace à suivre uniquement les fonctions du noyau appelées par un processus.
- process-ftrace.c : Nous pouvons prendre comme exemple ce simple programme C.
1
2
3
4
5
6
7
int main(){
while(1){
sleep(5);
}
return EXIT_SUCCESS;
}
- Obtenir le PID du processus : Nous pouvons utiliser la commande
$ ps -aux, mais parce que nous utilisons une console série, on préfère mettre le processus en arrière-plan et obtenir en retour son PID (voir l’image ci dessous).
- set_ftrace_pid : à présent, nous avons le PID du processus, affinons Ftrace pour suivre notre processus comme indiqué ci-dessous :
Maintenant, nous pouvons démarrer/arrêter la trace et lire le fichier de rapport comme suit:
Trace-cmd
Ftrace est fastidieux et nécessite une longue configuration avant que nous puissions avoir une trace. Le créateur de Ftrace « Steven Rostedt » a publié un outil Front-end pour Ftrace appelé Trace-cmd.
Installer Trace-cmd
Trace-cmd n’est pas disponible par défaut sur les distributions majeures, il faut l’installer :
$ sudo apt-get update $ sudo apt-get install trace-cmd
Commençons avec Trace-cmd :
-
Liste des fonctionnalités de Trace-cmd : il suffit de lancer la commande suivante :
$ trace-cmd -
Produire une trace avec trace-cmd
-
Lister les événements disponibles : **L’ensemble des événements pris en charge sera différent pour chaque système. En d’autres termes, ce sont les événements qui peuvent être tracés à l’aide de **trace-cmd.
$ trace-cmd list -
Démarrer trace-cmd : **la syntaxe générale pour démarrer **trace-cmd est la suivante :
# trace-cmd record -p traceur -e evenement1 -e evenement2 -e evenementN [programme args...]
-
traceur : **peut être l’un des types de traceurs disponibles sur **Ftrace (function, function_graph, …, etc).
-
evenement1, evenement2, …, evenementN : fonction à tracer (doit être disponible à partir de la liste retournée par « trace-cmd list »)
Remarque : si aucun programme n’est fournis en paramètre. « trace-cmd » va tracer tous le système.
- Lire la trace : **Trace-cmd peut lire le fichier « **trace.dat » qui a été généré après la fin du traçage. la trace peut être lu comme suit :
- Arrêter trace-cmd : même si trace-cmd a arrêté l’enregistrement, il est toujours en cours d’exécution. Nous devons complètement arrêter le traceur :
# trace-cmd reset
Traçage réseau avec trace-cmd
Trace-cmd permet de tracer un système distant. Ceci est idéal pour les platformes embarquées (Rasbperry PI, Beaglebone, …, etc.) qui n’ont pas assez d’espace pour enregistrer le rapport de trace.
Nous allons tracer l’utilitaire stress (qui augmente la charge de travail CPU et mémoire sur un système) à titre d’exemple. Nous devons d’abord l’installer sur la Raspberry PI 3.
pi@raspberrypi:~$ sudo apt-get install stress
Les étapes pour tracer un système à distance sont :
-
Configurer trace-cmd sur un ordinateur distant : **il suffit de lancer **trace-cmd en tant que serveur pour écouter sur un port particulier.
$ sudo trace-cmd listen -p 9999N.B : l’option -p permet de chosir un port. -
Configurer trace-cmd sur Raspberry PI 3 : ** Une fois que le serveur d’écoute sur l’ordinateur distant est démarré, on peut lancer le client **trace-cmd sur la Raspberry PI 3.
$ sudo trace-cmd record -e sched_wakeup -N IP-serveur_distant:9999 stress -c 4 -
Arrêter le serveur distant : Attendez que le programme sur le Raspberry PI soit terminé ou forcez-le à se terminer. Vous devriez voir quelques informations du coté du serveur (qu’on peut arrêter maintenant).
- Lecture et analyse du rapport trace-cmd : on peut lire le rapport en utilisant la commande « trace-cmd report » que nous connaissons déjà :
KernelShark
La lecture du rapport Ftrace peut être difficile. le troisième outil publié par « Steven Rostedt » est KernelShark qui est un parseur graphique des traces générées par trace-cmd.
KernelShark n’est pas disponible directement sous Linux, il faut l’installer :
1
sudo apt-get install kernelshark
L’utilisation de KernelShark est facile, nous avons seulement besoin de l’appeler et il cherchera un fichier trace.dat dans le répertoire courant (ou lui indiquer l’emplacement de ce dernier avec l’option -i).
1
sudo kernelshark
Un exemple sera plus parlant :
- Générer le fichier trace.dat : nous allons tracer les appels système :
1
sudo trace-cmd record -p function -l ‘sys_*’
- Parser le fichier trace.dat avec kernelshark : on doit le démarrer comme ci-dessous :
1
sudo kernelshark
La commande ci-dessus ouvre l’interface graphique « KernelShark« , qui montre l’activité enregistré sur chaque CPU.
L’IHM de kernelshark
Même s’il est facile de naviguer dans KernelShark, il regorge de fonctionnalités cachées qui ne sont pas faciles à découvrir.
- Disposition de l’IHM : KernelShark est simple mais requiert quelques minutes pour le comprendre.
- Zone d’information : C’est le haut de la fenêtre de KernelShark. Elle contient des informations constamment mises à jour.

Le champ « pointer » suit le curseur de la souris. Il indique le timestamp de l’évènement survolé par le curseur.
- Zone de titre : par défaut, montre tous les processeurs qui ont été tracés avec trace-cmd.
- *La listview : **qui affiche les événements capturés *(1 millions par page).
- Appeler les marqueurs : KernelShark prend en charge 3 marqueurs différents :
- Marqueur vert — Marqueur A : appelé avec un clic gauche de la souris sur la zone centrale.
- Marqueur rouge — Marqueur B : utilisez Maj + clic gauche de la souris pour l’afficher.
Comme pour le marqueur A, nous remarquons que la zone d’information graphique est mise à jour avec la position du marqueur B.
Si le marqueur A est présent, KernelShark mesurera la différence de position entre les deux (Marqueur A — Marqueur B) et enregistrera le résultat dans A, B Delta. Ceci est utile pour mesurer le temps passé à exécuter un événement particulier.
- Marqueur noir — Marqueur de Zoom : s’affiche si le bouton gauche de la souris est maintenu pendant une longue période. Il permet de zoomer ou dézoomer selon le sens de déplacement (un message explicatif sur le zoom s’affiche avec ce marqueur comme le montre l’image ci-dessous).
En effectuant un zoom, on peux visualiser la chronologie des événements comme sur la figure suivante :
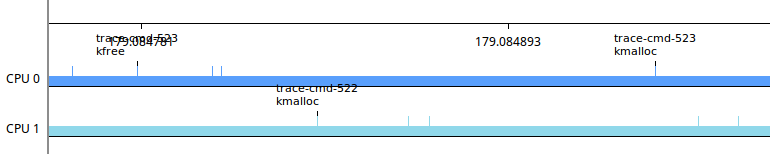
- Affichage des processeurs et des tâches :
- les CPU : Lors du démarrage de KernelShark, tous les processeurs sont affichés. Il se peut que nous ne soyons intéressés qu’à visualiser les évènements sur un CPU en particulier. Cliquez sur plots dans la barre de menu, puis sélectionnez CPUs. Décochez les CPU que vous voulez cacher. A titre d’exemple, gardons seulement CPU0 et CPU3 dans la zone centrale (voir l’image ci-dessous).
- les tâches : Contrairement aux processeurs, les tâches ne sont pas affichées par défaut dans la zone centrale. Nous pouvons changer ce comportement, Cliquez sur plots dans la barre de menu, puis sélectionnez Tasks. Sélectionnez les tâches à ajouter à la Zone centrale (voir l’image ci-dessous).

Conclusion
Nous avons découvert au cours de cette article le traceur Ftrace et son utilisation à partir de zéro.
Il reste encore des choses à voir qui ne sont pas abordés mais qui peuvent être consultés sur : https://github.com/jugurthab/Linux_kernel_debug/blob/master/debugging-linux-kernel.pdf.
Les prochains articles présenterons d’autres traceurs comme LTTng et eBPF.
Pour aller plus loin
Originally published at www.linuxembedded.fr on December 28, 2018.
That’s all folks
Did you enjoy it? If so don’t hesitate to 👏 our article or subscribe to our Innovation watch newsletter! You can follow Smile on Facebook, Twitter & Youtube.