
Smile Innovation Watch #14

*This content was sent on june, 7th via our Tech Watch Newsletter*
Is it already June? Damn how times fly 😅 It starts to be warm enough to enjoy a picnic in parks, outdoor fountains, using the 🚲 bicycle or your favourite 🛴 e-scooter and has a fun ride to/from work.
This edition of the tech watch is full of 🤖 #robots and, one more time, #AI. It could sound a bit repetitive but they are two fields where improvement are made every single day and not small ones but giants leaps. Also present: #contactless payment, #masssurveillance, how to fool #computervision, Facebook statements in court about so-called privacy.
This is Smile’s Innovation Watch.
Innovation •/ˌɪnəˈveɪʃən/
NYC Subway rides will be able to swipe in with Apple Pay starting Friday
That’s good news for all commuters of NYC, Apple Pay with their dedicated framework for transportation services is now rolling out after months of testing. But the head start will be very short for Apple since Visa & Mastercard is enabling tap payment & access for ground transportation services. It’s well done technically and we’ll work kinda like an oyster card. You’ll pay by tapping but only the difference between what you already paid and the several prices existing. Ex: Tap the first time, pay a 1-time ticket. Second time? You may get charged just 20 cents for upgrading to a half day ticket.
Domino is using computer vision and AI to check pizza before delivery
It’s called “DOM Pizza Checker” and have two cute LED eyes and a big smile, and it is the new companion in Domino’s kitchen in Australia and New Zeland to ensure the pizza will look as it should, and if it doesn’t, staff will make it right.
Google Translate may leave the text part of the translation process
Google is experimenting on phoneme to phoneme direct translation and the results are promising. Usually, when you want to do translation you first translate voice to text, then apply translation on it, and then vocalize it back. That involves a lot of possible mistakes since you have 3 steps of transformations where you are trying to guess what the result could be. Removing the textual part leads to better translation in most of the case Google tries. And they didn’t stop there, phoneme to phoneme translation let them experiment voice pattern transfer, meaning tomorrow, it will be your voice that will be used to talk in the translated voice synthesis, without any need of pre-training.
Ford is experimenting Self Driving delivery van with Legged Robot
It’s as creepy as it’s innovative and marvellous to watch. Ford is experimenting with Digit robot not just drive until from of your home, but have robotic labour coming to deliver the package right in front of your door.
Privacy •/ˈpɹaɪ. və. si/
People in Portland have digital clones without knowing it
Working with Alphabet’s project Replica, the city of Portland has greenlighted data collection at the scale of the entire metro area. But the scary thing is Replica isn’t using sensors, beacons, cameras, IoT or WiFi hotspots/kiosks but data coming from app publishers, mobile location data aggregators and telcos. The idea behind Replica is to understand how people are moving in the city and using public infrastructure, but also the impacts of Uber or Lyft on traffic congestion, how many cyclists use protected bike lanes, etc. The cherry on top: they are able to differentiate if you’re going to work, doing shopping… The issue is, they “may” also disclose “demographic information” like age range, race, gender, household size and income-level …
Don’t want to be tracked by computer vision? Wear this

While people in London have been forced by police to show their face in front of a face-tracking camera in order to participate against their will to a giant testing face of computer vision x tracking software, the end of public anonymity is a topic that is gaining more and more importance. In a paper shared a few weeks ago, students show how just a printed image hanging around your neck can act as an invisibility cloak while you’re still complying with the more and more law that prohibits you to cover your face in public area, even if face tracking experiments are running.
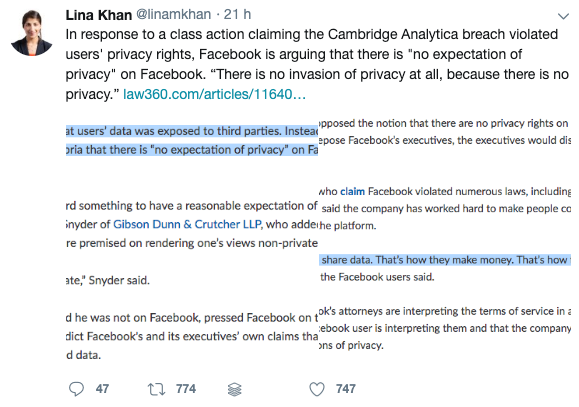
There is no privacy breach at Facebook, because there’s no privacy at all on Facebook
Openness • /ˈəʊ.pən/+/nəs/

Doggo, the open-source legged robot from Stanford
The estimated total cost of this robot: less than $3,000. This still a bit pricy for a one-man geek team, but in the world of legged robots, it’s a revolution. Because of the price (proprietary robot Minitaur is $11,500 and it’s the first less expensive), but also because of the performances: better torque than the Minitaur and better vertical jump than MIT’s Cheetah 3 robot.
Fun • /fʌn/

Samsung’s new AI can create talking avatars with a single photo
Samsung overcomes the need for a 3D modelling to create talking avatar thanks to their Moscow’s research centre. The idea to not train a model for a person but create a meta-model, able to get only one picture in entry and, if it detects the good landmark on the face of the picture presented, will generate the movies from it. It can be applied to celebrity but also painting or famous pictures. Obviously, more pictures in entry lead to better results but not every time, you’ll see some examples in the following video where 8 pictures in entry give better results than 16.
That’s all folks!
Did you enjoy it? If so don’t hesitate to 👏 our article or subscribe to our Innovation watch newsletter! You can follow Smile on Facebook, Twitter & Youtube.