
LSTM, Intelligence artificielle sur des données chronologiques

Ou comment un réseau de neurones peut interpréter une série de données dite “temporelle”
Si vous avez un tant soit peu travaillé avec des réseaux de neurones, vous avez certainement remarqué que, généralement, nous travaillons avec des données “d’entrée” ponctuelle. En d’autres termes, une image, un jeu de valeurs… mais il est possible de travailler avec des données temporelles telles que des valeurs boursières sur un laps de temps, des “frames” de vidéo, etc… Pour cela, la reine des topologies se nomme LSTM. Dans cet article, nous allons tenter de vulgariser son fonctionnement afin que vous puissiez vous pencher sur le sujet plus sereinement à l’avenir.
L’intelligence artificielle est un domaine actuellement en pleine effervescence, et des découvertes incroyables émergent chaque jour, avec de nouveaux domaines d’application. Nous avons, par exemple, déjà étudié les réseaux de neurones et les crypto-monnaies dans un article que nous vous conseillons de parcourir également.
https://medium.com/smileinnovation/how-to-make-profits-in-cryptocurrency-trading-with-machine-learning-edb7ea33cee4
Mais avant d’aller plus loin, il est bon de préciser les définitions de base afin que nous soyons tous sur la même longueur d’onde pour la suite de l’article.
Le Machine Learning, c’est quoi ?
Champ d’étude de l’intelligence artificielle, concerne la conception, l’analyse, le développement et l’implémentation de méthodes permettant à une machine (au sens large) d’évoluer par un processus systématique, et ainsi de prévoir des résultats par** apprentissage**, et non par la création d’algorithmes complexes qui, potentiellement, pourraient d’ailleurs fonctionner avec moins de précision. (Wikipedia)
Une des méthodes d’apprentissage la plus connue est le réseau de neurones. Le réseau de neurones est une méthode de construction de modèle qui peut, par le biais de données d’entraînement, “apprendre” à prédire des valeurs par la suite. On peut s’en servir aussi bien pour analyser des données simples (données chimique, choix d’utilisateur, capteurs de température…) que des données très complexes comme des images, des vidéos, le cours de la bourse, etc…. Tout le monde a ce cliché de l’école primaire des années 70, où lorsque l’élève récitant ses tables de multiplication se trompe et que son professeur sort sa règle et lui tape sur ses doigts en lui disant “c’est faux, tu t’es trompé recommence”. Le réseau de neurones fonctionne de la même façon, nous allons lui faire recommencer la phase d’apprentissage tant que nous n’avons pas le résultat souhaité.
En termes d’expériences, deux cas de figures s’offrent à nous :
-
les expériences sont indépendantes les unes des autres
-
les expériences sont sous la forme de séquences temporelles
Le problème
Un réseau de neurones classique permet de gérer les cas ou les expériences sont indépendantes les unes des autres. Lorsque les expériences sont sous la forme de séquences temporelles, une nouvelle structure a été inventée : les réseaux de neurones récurrents. Cette nouvelle structure introduit un mécanisme de mémoire des entrées précédentes qui persiste dans les états internes du réseau et peut ainsi impacter toutes ses sorties futures. Le réseau de neurones Long Short Term Memory (LSTM) est l’un des plus connu.

Un peu d’histoire
Bien qu’il soit connu depuis 1997, l’architecture de neurones Long Short Term Memory connait un essor plus important depuis quelques années, cela est dû au fait que, comme pour la plupart des modèles neuronaux, nous profitons de l’évolution des performances de machines, mais aussi depuis que le machine learning dispose d’outils mathématiques puissants pour résoudre les fameux problèmes de rétropropagation. En effet, c’est en 1997 que le réseau de neurones LSTM a été conceptualisé par Sepp Hochreiter et Jürgen Schmidhuber.
Le réseau de neurones Long Short Term Memory (LSTM) est utilisé sur des données triées temporellement. Dans certains cas d’usage, il est important de savoir quelles décisions ont été prises dans le passé afin de prendre une décision optimale à l’instant t.
Cas d’utilisation
Depuis 2016, il est présent un peu partout dans certaines fonctionnalités et applications que vous utilisez tous les jours. Google l’utilise, par exemple, pour son assistance vocale sur mobile. Apple, quant à lui, l’implémente dans sa fonctionnalité “QuickType” qui facilite l’écriture sur iPhone.
Cet article n’a pas pour but de refaire l’enseignement du LSTM mais de proposer une vulgarisation à la communauté française. Cependant si vos recherches vous mènent dans des contrées plus techniques, je vous conseille la lecture de “Understanding LSTM Networks” (27 août 2015, par Christopher Olah) ou plus récemment avec l’article “Understanding LSTM and its diagrams (13 Mars 2016 par Shi Yan).
Illustrons le principe
Pour bien comprendre le concept du réseau de neurones LSTM, nous allons imaginer une petite mise en scène : un club assez réputé organise une soirée. Des influenceurs sont attendus. Pour faciliter l’accès, deux agents de sécurité sont réquisitionnés :
-
un agent de sécurité pour les anciens clients.
-
un agent de sécurité pour les nouveaux clients.
Le premier agent sera en charge de s’occuper exclusivement des anciens clients, il va décider quels anciens clients vont être autorisés à passer l’entrée. Pour ce faire, l’agent de sécurité détient une liste de clients. Ceux présents sur la liste ont l’autorisation de passer la soirée dans le club. Les “critères” de sélection pour apparaître dans la liste sont :
-
avoir beaucoup consommé lors des précédentes soirées.
-
avoir eu un comportement irréprochable.
Les anciens clients se présentent à la porte d’entrée et exposent leur carte d’identité à l’agent de sécurité, il vérifie sa liste et refuse ou accepte l’accès au club des anciens. En fin de soirée, l’agent de sécurité met à jour sa liste d’anciens clients qui servira aux prochaines soirées.

Le second agent de sécurité est moins sélectif à l’entrée, mais il va être bien plus strict à l’intérieur. Les nouveaux clients se présentent à l’entrée, l’agent de sécurité laisse passer tout le monde peu importe leur tenue, ici le mot d’ordre est “ laissons-leur une chance“. Une fois que tous les nouveaux clients sont à l’intérieur du club, l’agent de sécurité décide, à son tour, de rentrer dans le club. Lors de la soirée, tout les clients sont scrutés et leur comportement scrupuleusement évalué par l’agent de sécurité. La notoriété du club est en jeu, les clients qui vont être agressifs, éméchés, ou peu respectueux vont être rappelés à l’ordre par l’agent de sécurité. Les nouveaux clients qui consomment et qui contribuent à une bonne ambiance vont être notés sur une liste. Les clients présents sur cette liste auront le privilège d’être considérés comme bons clients.

En fin de soirée, les deux agents de sécurité se réunissent afin de fusionner les deux listes pour n’en former qu’une seule qui fera office de nouvelle liste pour les prochaines soirées.
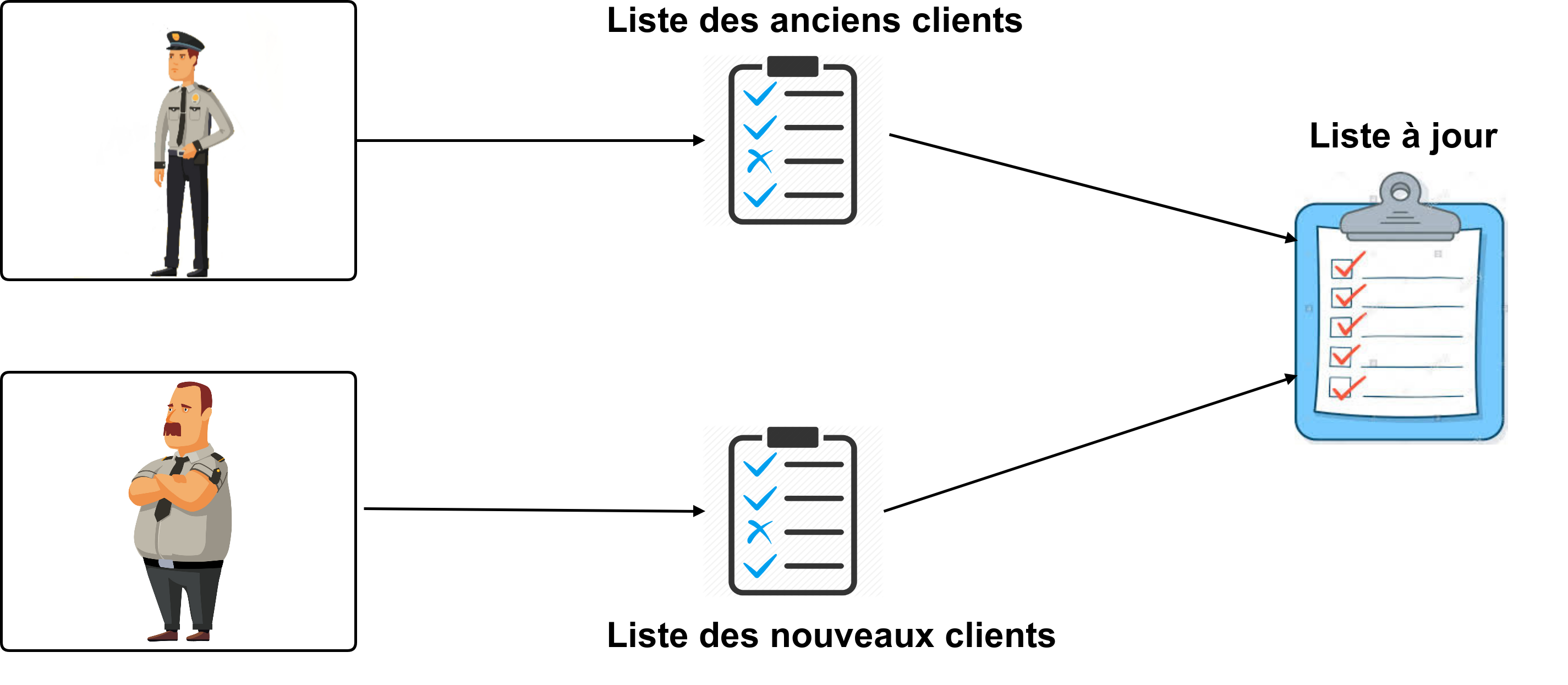
Club = LSTM ? (Où veulent-ils en venir ? )
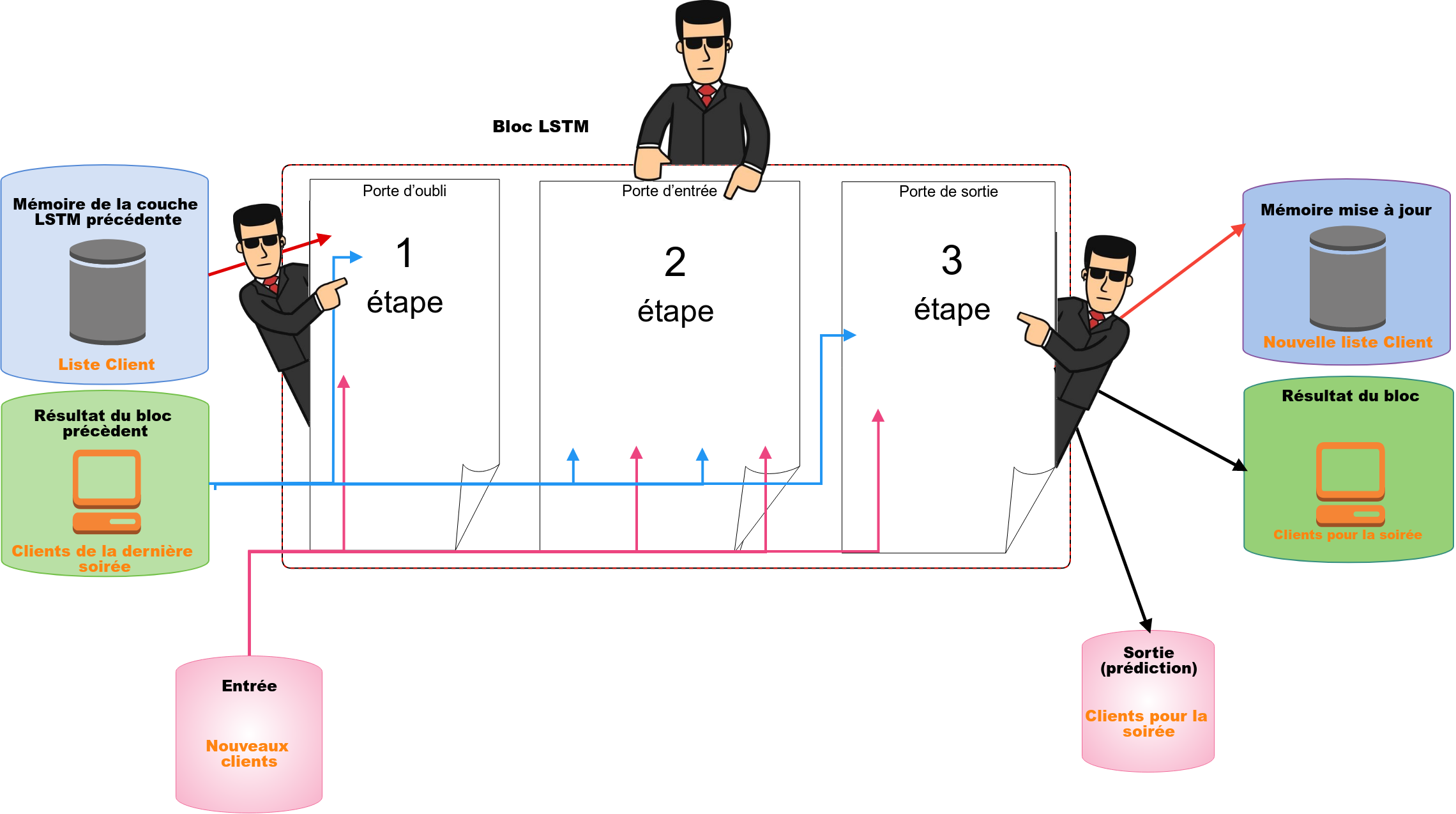
La gestion de la mémoire d’un bloc LSTM à l’autre fonctionne de la même manière. Concrètement, un bloc LSTM comporte 3 portes : une porte d’oubli qui jouera le rôle d’agent de sécurité en charge des anciens clients, une porte d’entrée qui jouera le rôle d’agent de sécurité en charge des nouveaux clients ainsi qu’une porte de sortie que nous expliquerons dans les parties suivantes.
Struture du réseaux LSTM (Long Short Term Memory)
Une couche LSTM est donc plus ou moins illustrable de cette manière :
Porte d’oubli
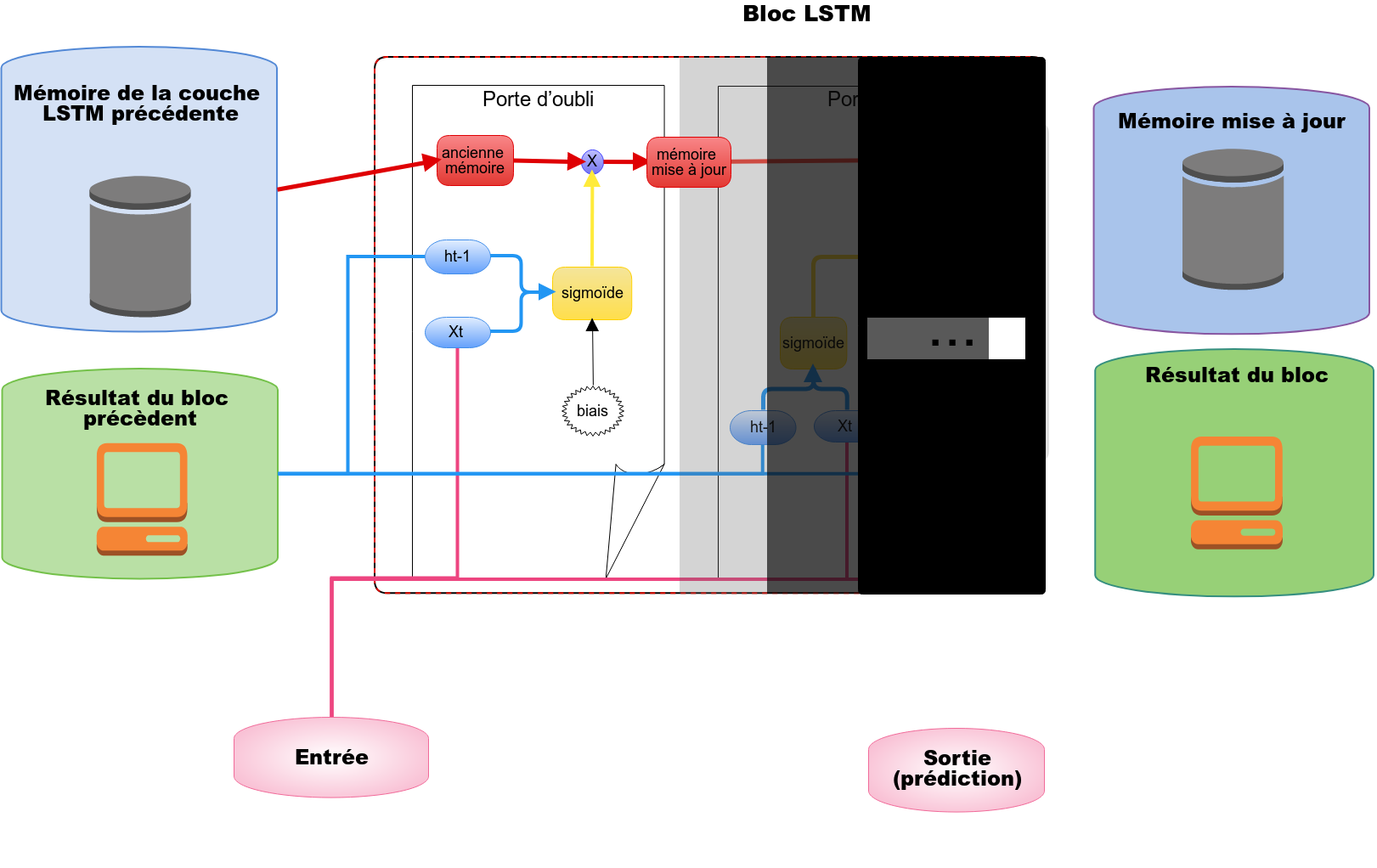
La porte d’oubli va se charger de filtrer les informations contenues dans la cellule mémoire précédente. Parmis ces informations, certaines vont être plus pertinentes que d’autre. Pour décider quelles valeurs vont être autorisées à passer, nous allons utiliser différents calculs mathématiques :

xt correspond aux données entrantes dans le réseau de neurones, ht-1 *correspond à la valeur de sortie qui a été prédite par la couche LSTM précedente. D’un point de vue mathématique, *[ht-1,xt] désigne la concaténation des tableaux *xt *et *ht-1. *Comme dans un réseau de neurones classique, Wf correspond au poids des neurones et bf correspond au biais (le biais est considéré comme un degré de liberté supplémentaire) d’un réseau de neurones. Tout ce beau monde est passé comme paramètre à une fonction de transfert nommée sigmoïde. En sortie, la fonction sigmoïde nous renvoie un entier compris entre 0 et 1.
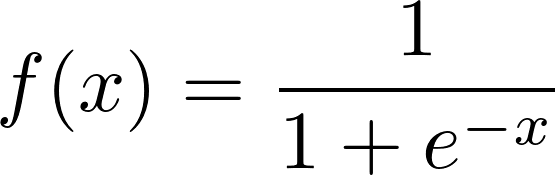
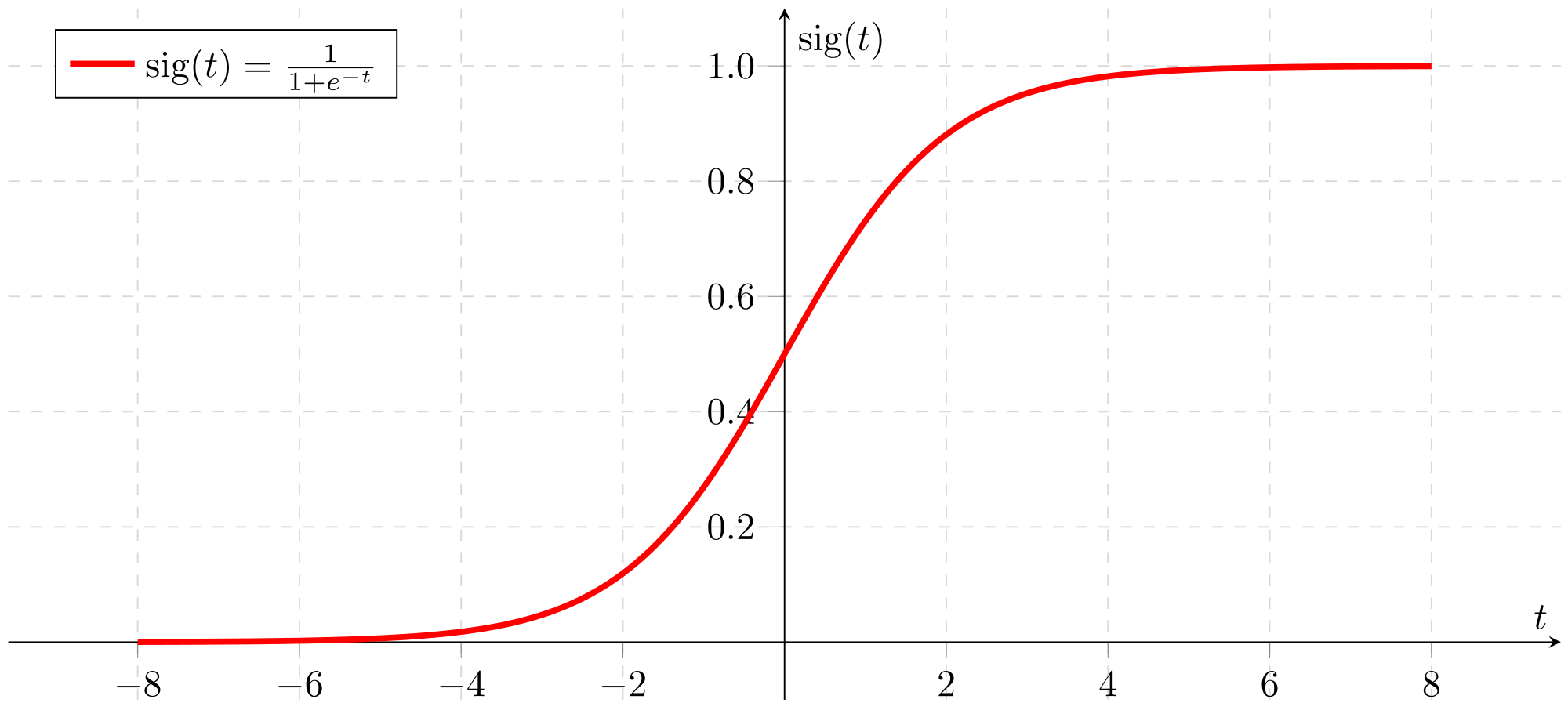
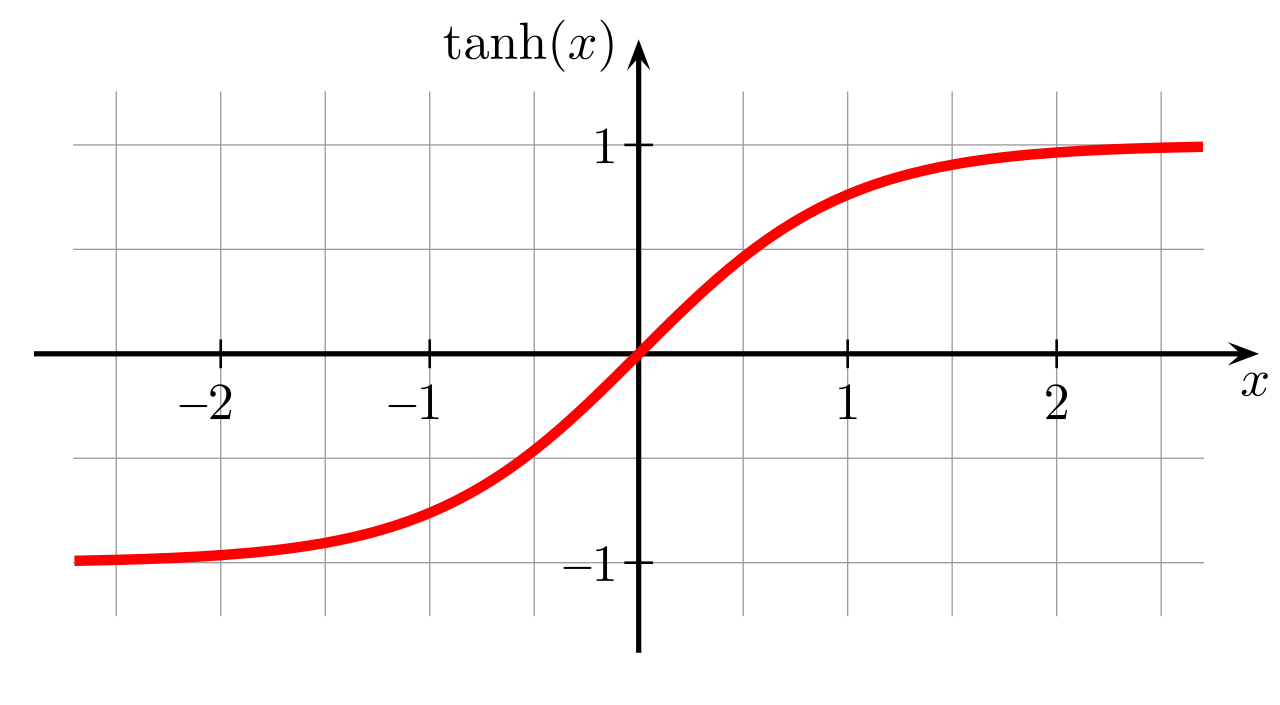
Si vous vous demandez pourquoi une fonction sigmoïde est utilisée, la réponse est : juste parce qu’elle est sympa et par simple hasard… trêve de plaisanteries ! En vérité c’est bien plus compliqué. Je vais vous donner quelques pistes et à vos claviers pour les recherches : Elle représente la fonction de répartition de la loi logistique et est souvent utilisée dans les réseaux de neurones parce qu’elle est dérivable en tout point, ce qui est une contrainte pour l’algorithme de rétro-propagation qui a permis de créer des réseaux multicouches. Et enfin, chose intéressante, cette fonction a une tendance à lisser les valeurs de sortie.
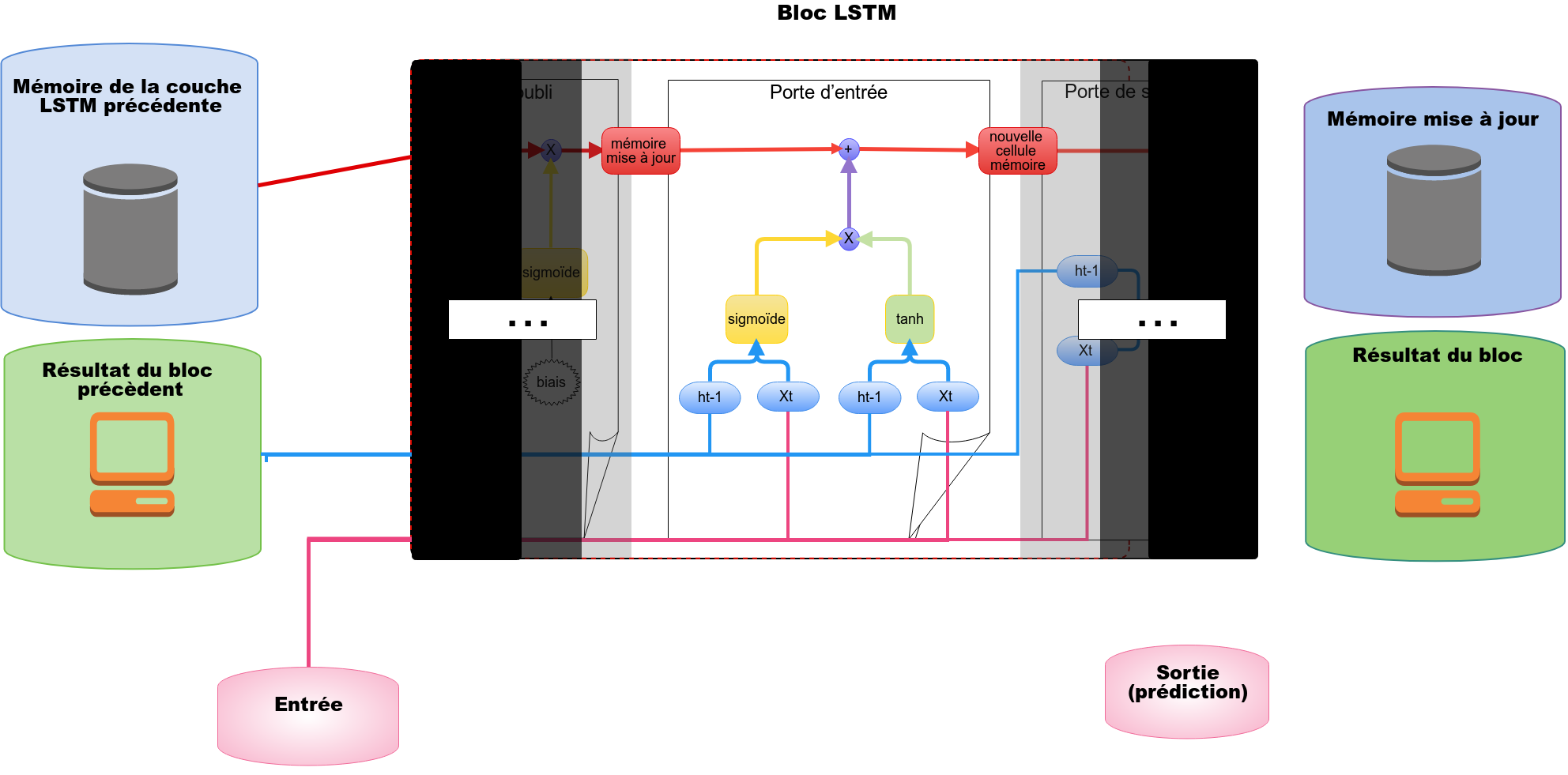
ft est donc un tableau de valeurs comprises entre 0 et 1. Pour savoir quelles valeurs de la cellule mémoire précédente Ct-1 vont être autorisées à passer, nous allons appliquer la multiplication terme à terme entre* ft* et Ct-1. Si, lors de cette multiplication la valeur de sortie est proche de 1 alors la valeur en question (valeur contenue dans Ct-1) est autorisée à passer. Dans le cas contraire, l’information contenue dans Ct-1 est ignorée si la multiplication donne une valeur proche de 0. Toutes les valeurs qui ont réussis à passer sont stockées dans C1.
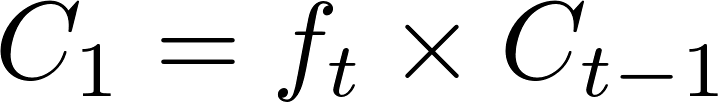

Avez-vous compris ?
La porte d’oubli se charge uniquement de filtrer les anciennes valeurs contenues dans la cellule mémoire précédente.
Porte d’entrée
Après avoir mis à jour les valeurs présentes dans la cellule mémoire précédente, il est temps de décider quelles nouvelles informations (nouveaux clients) vont être autorisées à être stockées dans la cellule mémoire.
La porte d’entrée va se charger de décider quelles nouvelles valeurs provenant de *xt *(valeurs entrantes du LSTM) vont être autorisées à passer.
Certaines entrées vont être plus pertinentes que d’autres. Celles qui sont pertinentes vont être stockées dans la cellule mémoire qui va servir à la prise de décision à l’instant t et peut-être pour l’instant *t+1 *si la porte d’oubli lui autorise l’accès. Comme pour la porte d’oubli, différentes formules mathématiques vont être nécessaires pour savoir quelles informations vont être autorisées à passer :

Dans un premier temps, une fonction sigmoïde est nécessaire pour décider quelles nouvelles entrées seront susceptibles d’être stockées dans la cellule mémoire. it** **sera un tableau et chacune de ses valeurs sera comprise entre 0 et 1. Dans un second temps, nous allons faire la même chose sauf que la fonction d’activation utilisée est la fonction tangente hyperbolique (c’est une sigmoïde centré entre -1 et 1).
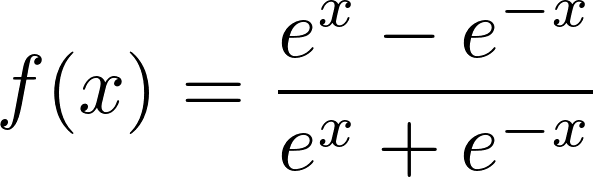
C~ est un tableau dont chaque valeur sera comprise entre -1 et 1. C~ contient les valeurs candidates à être stockées dans la cellule mémoire. La multiplication terme à terme entre it et C~ nous permettra de savoir quelles valeurs vont devoir être stockées dans la cellule mémoire. Si le résultat est proche de 1 alors nous allons stocker la valeur correspondante dans la cellule mémoire, au contraire si le résultat est proche de 0, l’information sera bloquée. La nouvelle mémoire sera donc :
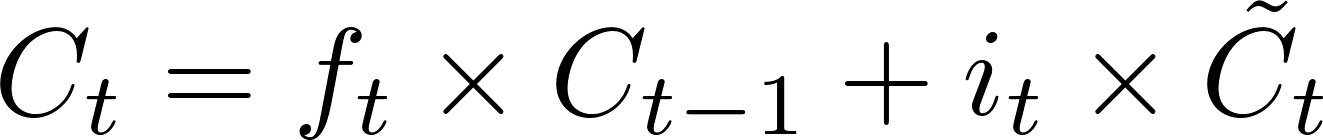

En bref
La porte d’entrée va, parmi les nouvelles entrées, laisser passer les informations qui sont pertinentes (nouveaux clients). Ces valeurs-là seront stockées dans la cellule mémoire et auront une importance dans la prise de décision à l’instant t et peut-être pour l’instant t+1.
Porte de sortie
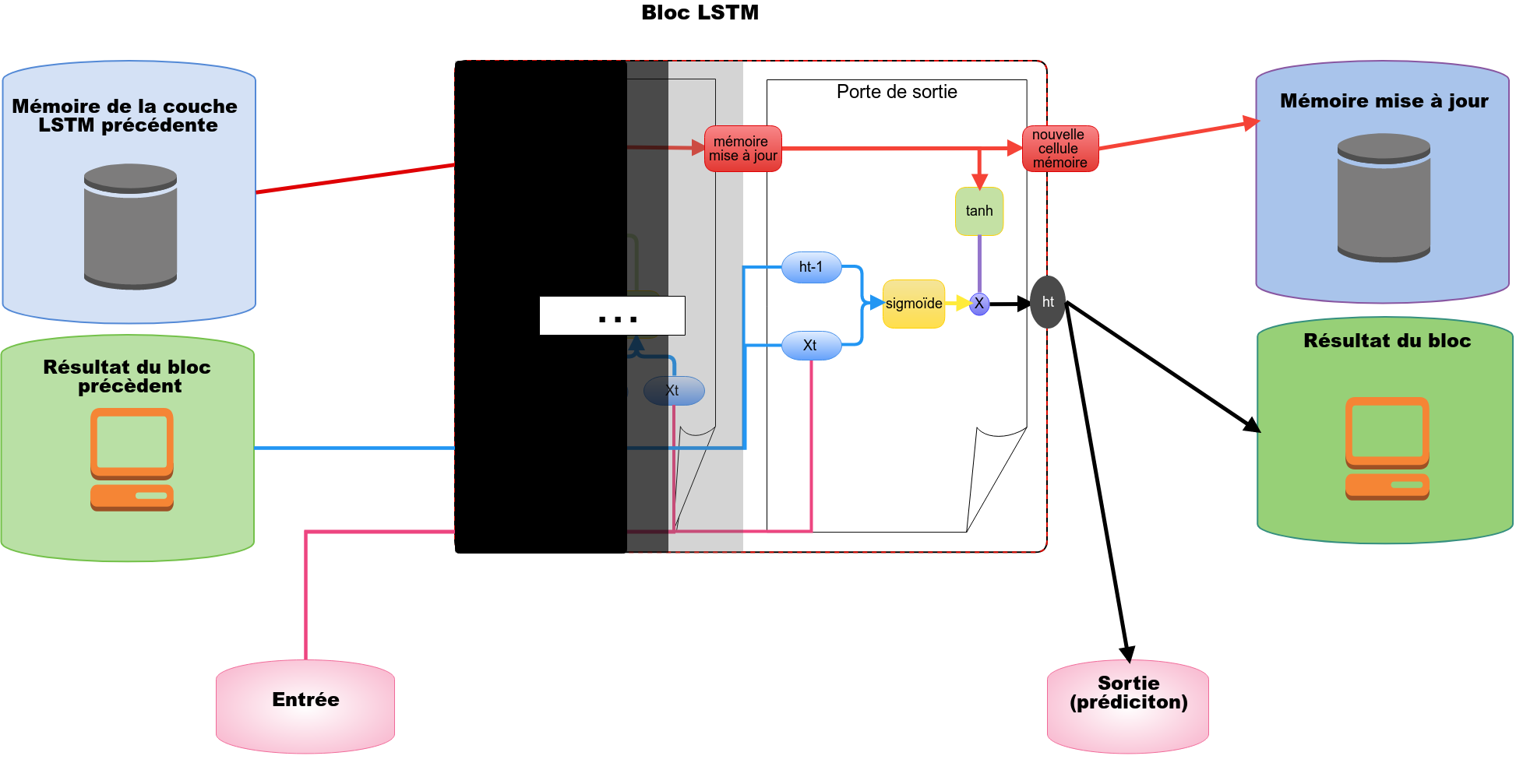
Il est temps, en fonction de l’entrée (xt), de fournir une décision ht à la fois pour le bloc LSTM suivant ainsi que pour l’utilisateur. La prise de décision *ht *est calculée de la sorte :
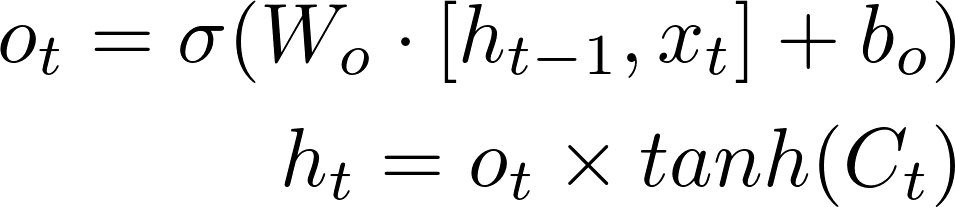
La sortie* ht* va dépendre des informations présentes dans la cellule mémoire Ct *ainsi que des informations entrantes *xt dans la couche LSTM.
Long Short Time Memory
Dans un soucis de chronologie, ils est important d’assembler plusieurs bloc LSTM afin de créer une série temporelle qui servira à la prédiction d’une action.

Conclusion
Le réseau de neurones LSTM est utilisé dans plusieurs domaines. En effet, savoir ce qui s’est passé précédemment afin de prédire une action à l’instant t est très important.
Afin de détecter et donc de prédire les pannes de leurs machines, les industriels vont étudier chronologiquement chaque paramètres de leurs machines (température de la machine, date de la dernière réparation de la machine, nombre de pièces fabriquées…). Amazon l’utilise également dans sa reconnaissance vocale utilisée par Alexa, et oui grâce au LSTM la voix d’Alexa contrairement à ce que l’on peut croire n’est pas un enregistrement de voix féminine humaine. le LSTM peut bien entendu être utilisé pour reconnaître un mouvement (en combinaison avec des couches convolutionnelles) puisque nous devons nous baser sur des “frames” dans un temps donné, ou encore pour étudier le cours de la bourse comme nous l’avons fait dans l’article dont le lien se trouve en haut de cette page.
En bref, LSTM est une topologie neuronale extrêmement utile à partir du moment où une “série temporelle” de données est en jeu.
L’explication d’une telle architecture n’est pas évidente, c’est pour cela que nous avons introduit un exemple compréhensif. Si des articles techniques tel que celui-ci vous intéressent, n’hésitez pas à nous proposer d’autres pistes à explorer.
Avez-vous apprécié l’article ? Si oui, n’hésitez pas à 👏 notre article ou abonnez-vous à notre newsletter Innovation watch! Vous pouvez suivre Smile sur Facebook, Twitter et Youtube.
Co-auteur : Quentin Le Baron, Youcef Messaoud
Références