
Your private GPT to chat with your documents

A step-by-step guide to build a chatbot that can answer any questions about what’s in your documents
What if we build another chatbot?
People accustomed to the chatbot concept, and who run into such projects know how frustrating it is to get a low or average accuracy response, despite having spent days defining your chatbot intents and entities. And knowing that this process needs to be run on a regular basis to keep the chatbot up to date, it lowers opportunities and success for chatbot projects.
But with the advent of Large Language Model (LLM) technologies, and in particular ChatGPT, it is necessary to revive this subject.
And to do so, I would like to answer the following question: leveraging on LLM, is it possible to build a chatbot specialised in a specific domain? With perhaps the constraints of private data, what would be the build and maintenance effort?
Living for almost 20 years in Luxembourg, I first thought of a local industry, which led me to the following idea: how about a chatbot specialised in the financial industry.
And one playground for that could be to use all the public data from the Commission de Surveillance du Secteur Financier (CSSF).
The CSSF is a public institution which supervises the professionals and products of the Luxembourg financial sector. Their publication and data cover the regulation of the local finance industry, but also news, reporting and statistics.
With all this public data we will investigate how we built a “Q&A” chatbot type, but also see how we can have this chatbot running privately. This chatbot will allow us to “chat with the CSSF information”
A recap of the GPT usage and principles
Before we get into the details of this proof of concept, we need to understand some fundamental principles of LLM.
LLM models belong to the generative AI model family. These models use neural networks to identify the patterns and structures within existing data to generate new and original content. These models are not able to reason, their generative process is purely statistical, based on their training data set and parameters.
In particular an LLM model is able to create a text from another starting textual element. This starting textual element (“seed text”) will have an impact on the generative processing and on the generated content variation. Its principle is just to predict the most probable next word in a sequence of words.
Under the hood, LLM models are using an IA technique named vector embeddings, that is important to understand for the next steps of this proof of concept.
Vector embeddings are numerical representations of words, figures of speech, or other linguistic elements as vectors. These representations capture the semantic relationships between words. This allows natural language processing algorithms to work more efficiently.
Also, by representing words as vectors, we can perform mathematical operations on them, making it easier for algorithms to sift through massive amounts of text data and identify meaningful patterns.
This approach is the cornerstone of all innovative models, as it allows programmers to create software able to understand human language.
Some well-known uses cases are:
- Text classification
- Word similarity
- Named Entity Recognition
- Text Generation
- Machine Translation
For this proof of concept, we will rely on two of them: text generation and semantic similarity.
Prompt engineering
As explained earlier, LLMs are good for a specific task, which is text completion: generate content following a seed text.
OpenAI ChatGPT (gpt3/gpt4) model has been especially trained to generate content in a conversational context, meaning what it will produce will be more suitable for a “chat” or Q/A usage.
So when using a ChatGPT model to generate content that must be the answer to a question you also need to create a seed text. This text, also named “prompt”, must contain the user question and any other information (context, discussion history, …) to make sure you will get the expected answer.
To create this seed text, a lot of techniques and best practices exist. Using them is called “prompt engineering.”
One important constraint for the prompt is its size limit. This limit is a technical requirement from LLM models due to their internal mechanism (“attention window size”). This limit is counted in “token”, referred to as terms or words. This limit is different from one model to another, GTP3 limit is 4096 tokens, while GPT4 it is 8000.
GPT Prompt
To illustrate this prompt concept, we can look at how the ChatGPT API is managing the requests, with a simple example.
Let’s imagine we want our AI assistant to be a regulatory framework expert and Super Mario fan. And we want this assistant to make a joke about mixing these two elements.
To do so we have to prepare a prompt that explains this context and initiate the conversation. The ChatGPT prompt formalism describes different elements to use:
- System text: to describe the role and mission of the assistant
- User text: the user question
- Assistant text: the generated content
Let’s play with ChatGPT:
As request we will use:
System: You are a regulatory framework expert for a fund manager in Luxembourg, and a Nintendo Super Mario fan. Invent a short joke mixing regulatory expert and the universe of the Super Mario game
User: I have a good one, do you know the commonalities between
As answer we got:


Assistant: Super Mario and a regulatory expert in Luxembourg? They both navigate complex worlds, collect valuable assets, and occasionally, they need to deal with a Bowser-sized compliance issue!
The assistant response is the direct completion of the user input.
In this example this is a first question answer, for subsequent requests, it is possible to add the previous question/answer elements to allow the model to have the chat context before generating its next answer.
You can also use a more regular API for text completion, that will only take text as input and will return the text completion.
Specialised chatbot with your private ChatGPT
The elephant in the room
OpenAI ChatGPT, as available publicly, will produce content according to its current training, based on a training data set built by OpenAI in 2021.
So when you are using the OpenAI ChatGPT chatbot (either v3.5 or v4), its answers will be limited by its knowledge cut-off (September 2021).
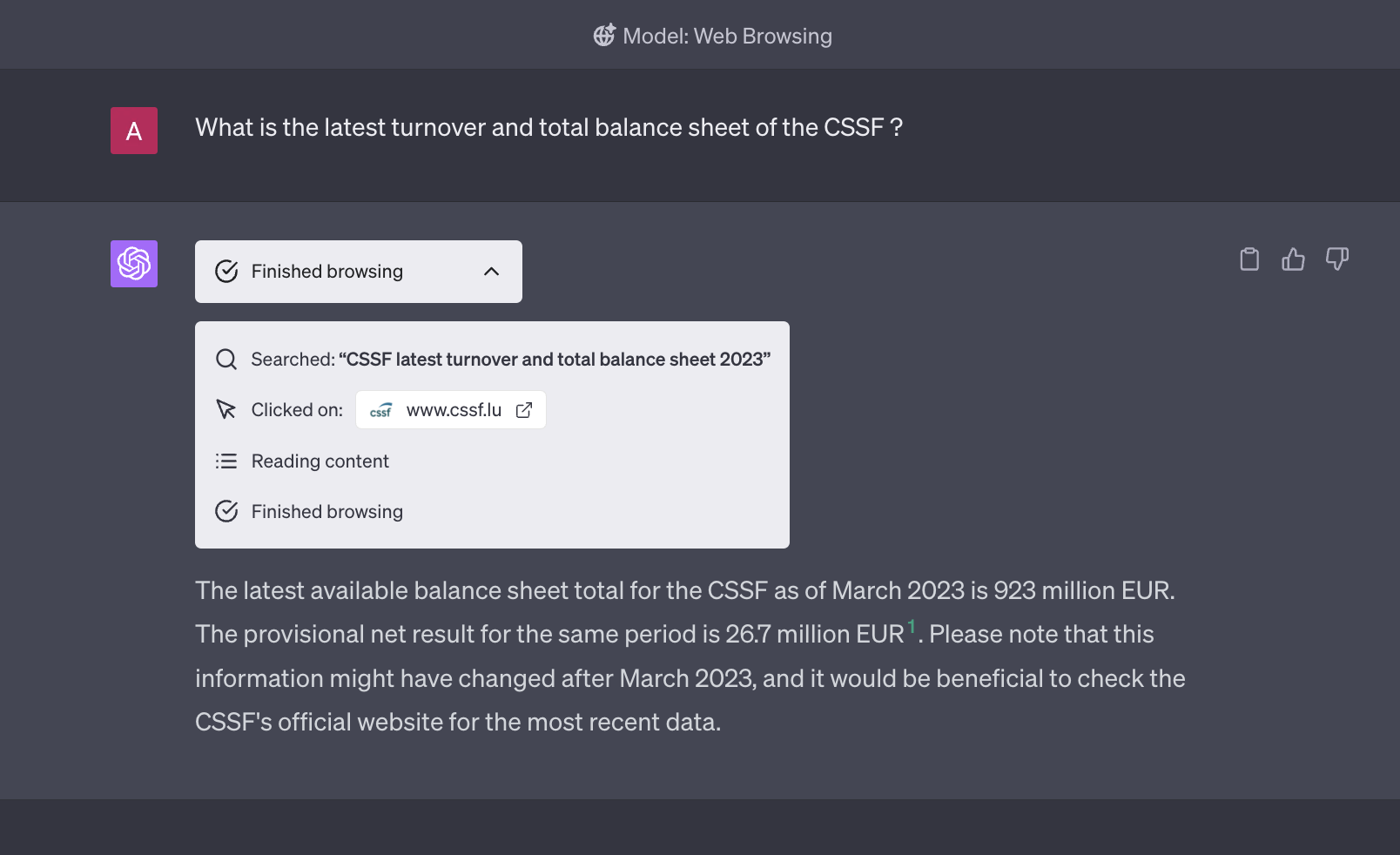
OpenAI has announced a few days ago that its ChatGPT has now the ability to automatically retrieve public data from the Internet, to generate answers. This definitely opens up a broad range of use cases we can’t yet grasp, but we still are at the assumptions phase (and we will see in this document that the current results of this new feature are not yet fully reliable).
Also, although its general public access is very convenient, it also involves disadvantages in terms of security:
- Risks of private data leakage: any question that contains sensitive or private information will go through OpenAI internal processing, so it can be captured.
- To deal with sensitive subjects or to avoid the hijacking of the discussion, the prompt engineering is critical to control the scope of the responses. Prompt is not available with the ChatGPT web application but only with the public API.
In other words, at the moment, building a chatbot based on LLM that can produce answers with specific content (public or private) and compliant with a data privacy policy, you need to:
- be able to inject in the prompt private or public content related to the user question, so the answer can be elaborated with this specific context, to overcome the model knowledge limitation.
- runs a private LLM model, or at least a controlled environment that includes private data leakage risk mitigation.
For this PoC, to stick to the initial goal (specific domain knowledge, private data), we have to look for alternatives to the regular ChatGPT API.
Alternatives
Two possible alternatives:
- If it fit the needs, use an open-source model (i.e. LLaMa, Bloom, Stanford Alpaca model), on your own infrastructure.
- Use a private instance of a well-known LLM model managed by a public cloud provider. Several offers have been launched by the main cloud providers. Something very interesting, available at the moment, is the partnership between OpenAI and Microsoft: in Azure you can have your own private instance, based on GPT (v3 or v4) running only for your own purpose. These private instances can also be fine-tuned to be more adapted to your use case.
To keep things short and simple, the choice between the two approaches mainly depends on these points:
- Where the model runs, and how it is maintained
- The expected accuracy and performance
Where the model runs and how it is maintained, depends on company policies and knowledge to operate this kind of technology:
- Running an open-source model requires you to manage a dedicated IT private infrastructure to make it available for your own purposes, and to support the associated costs (infrastructure and engineering).
- Choosing a model as a managed service, allows access to it in minutes. But like for any other managed services, its maintenance is done by a third party. The costs are generally based on consumption (per request).
Performance and accuracy of open-source models vary and some may be more specialised than others, as they have been trained with different training data sets.
For the sake of simplicity, this PoC will use the Azure OpenAI services, with GPT-4 and Ada models.
In the context, all the data exchange (questions, answers) remains in your Azure subscription. An important point is this privacy notice that describes the processing of the data. In summary from this notice:
- “No prompts or completions are stored in the model during these operations, and prompts and completions are not used to train, retrain or improve the models.”
- “The Azure OpenAI Service stores prompts and completions from the service for up to thirty (30) days to monitor for content and/or behaviours that suggest use of the service in a manner that may violate applicable product terms.”
- “Customers may request to modify content filtering and/or abuse monitoring by submitting a form. If a customer is approved and remains in compliance with all requirements to modify abuse monitoring, then prompts and completions are not stored.”
These points are important, and must be taken into account while building a service that will rely on this technology. And to some extent, the same question has to be answered when using an open-source model running on your own IT infrastructure, to prevent any similar abuse.
The Chatbot
What we want with this chatbot is to be able to ask questions about the finance regulation in Luxembourg, about the CSSF, and also to be able to answer questions from subject matter experts. And the answer must only be based on the CSSF public data and not something the bot would elaborate from its initial “knowledge”.
To summarise the usage of this chatbot, it must be able:
- To answer generic questions about the CSSF (as public institutions)
- To answer generic questions about the CSSF circulars (documents describing the regulatory framework)
- To answer questions about one or more specific CSSF circular
- To be restrained from answering any other kinds of questions. So to keep the chatbot answering only questions related to the CSSF, nothing else.
To leverage on CSSF public data to answer the questions, we must also be able to find in these data what is relevant for the current question. This is where the embedding principle makes sense: We can create a vector embeddings database of these public data Then we can benefit from this vectors database to search for semantic similarity between the question and the public data
The search result will allow us to inject the relevant content into the discussion context.
Chat orchestration
To build a chatbot that follows the expected usage, we need to orchestrate the discussion. This orchestrated discussion can be seen as a chain of actions. Here the main steps of this chain:
- Classify the intent of the question to use the correct prompt
- Based on the intent, be able to search for relevant contents and to inject a summary of them in the discussion context
- Generate a final answer, including any references to documents used to generate it.
CSSF data knowledge base
Before creating the chatbot, we need to have a knowledge base of the content that will be used to answer users’ questions.
As explained before, we will use the embedding principle to populate the database.
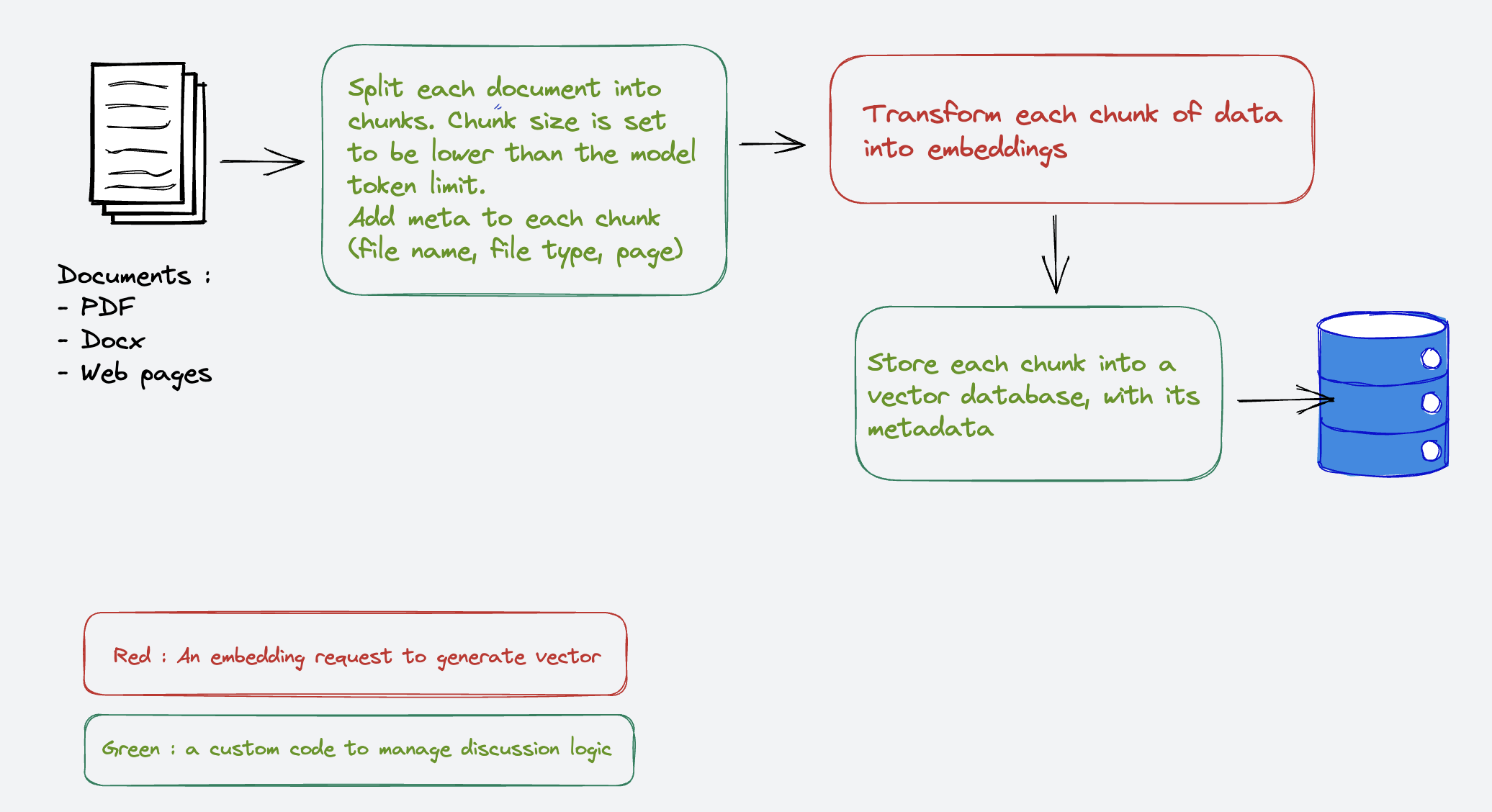
The first step is, of course, to list and collect the documents that will be part of this knowledge base. Any kind of information can be used here, as soon as we can extract text from them.
In our case we will use about 100 web pages from the CSSF public web site (https://www.cssf.lu/) and about 200 PDF and few Docx files published on this same website.
We will not store them nor host them, but we will just extract their text content and some metadata (source URL, page, file type, category), to allow documents filtering when querying the index, and also to give their references in chatbot answers.
To create embeddings, we have to use a specific LLM model, dedicated to this task and a specialised database capable of storing vectors, but also capable of running queries on them.
In our case, as we have chosen to use the Azure OpenAI’s service, we use a private OpenAI deployment in Azure. On this deployment we will enable the following OpenAI models:
- text-embedding-ada-002 : to transform a text into embeddings. This model creates vectors with 1536 dimensions.
- gpt-4 : to run text completion or chat
There are many databases available capable of storing and querying vector embeddings. To name a few of them:
They come with pros and cons, but for this use case we wanted something simple and not too expensive to run. A regular project would require to compare these products according to the expected SLA, features and company policies.
We started by trying Chroma, an open-source solution that requires you to run the DB engine. The similarity search worked great, but the filtering options were not yet satisfactory, as this project is still quite young.
We then switched to Pinecone, a SaaS solution, that offers a free plan for a limited amount of data, but with all the expected features to store vectors and run complex queries. This offer is enough for this use case, and as the test results were satisfactory, we kept it.
To create embeddings from text content you have to make sure your content size will not exceed the maximum number of tokens. When using text-embedding-ada-002 on Azure OpenAI, this limit is set to 4095.
So if a document we want to index is longer than this limit, it will not work. To avoid this issue, we have to split the text content in smaller chunks of text not longer than the model limit. Each chunk will be submitted to the embedding model to get a vector that will be stored in the database, with metadata related to the original data source.
In this PoC we have added the following metadata:
- The source URL
- The file name (if the source is a file, not a web page)
- The file type (pdf, docx, html, …)
- The page from which the chunk is coming from (if the source is a file, not a web page)
- A category, that is based on the kind of information the document contains:
- A web page
- A circular document (which is a specific publication from the CSSF)
- Everything else
- A CSSF Circular ID (which follow the pattern xxx/yyy) if the document is a circular
This metadata are important as they will allow us to scope the documents in which we want to run our query.
After all these steps, we can test a query. If I query the index, without any filters, with this sentence : “what is the CSSF turnover for 2021 ?” I get this result for the top-3 documents:
| Similarity score | Meta data | Chunk excerpt |
|---|---|---|
| 0.872185 | source: https://panorama-cssf.lu/wp-content/uploads/2022/09/CSSF_RA_2021_ENGLISH.pdf filename: CSSF_RA_2021_ENGLISH.pdf filetype: PDF cssf doc type: Unknown circularId: None |
I. Governance and functioning of the CSSF - 47 PROFIT AND LOSS ACCOUNT AS AT 31 DECEMBER 2021 Net turnover 123,971,886.24 Other operating income 13,464,127.03 Raw materials and consumables and other external charges 13,899,493.87 Raw materials and consumables 427,426.47 Other external charges 13,472,067.40 …. |
| 0.845972 | source: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2020.pdf filename: Balance_sheet_CSSF_2020.pdf filetype: PDF cssf doc type: Unknown circularId: None |
CSSF BALANCE SHEET 2020 PROFIT AND LOSS ACCOUNT AS AT 31 DECEMBER 2020 Net turnover 123,732,267.90 Other operating income 334,663.17 Raw materials and consumables and other external charges 15,034,725.51 … |
| 0.833736 | source: https://www.cssf.lu/wp-content/uploads/CSSF_RA_2021_FRANCAIS-1.pdf filename: CSSF_RA_2021_FRANCAIS-1.pdf filetype: PDF cssf doc type: Unknown circularId: None |
I. Gouvernance et fonctionnement de la CSSF - 47 COMPTE DE PROFITS ET PERTES AU 31 DÉCEMBRE 2021 Chiffre d’affaires net 123.971.886,24 Autres produits d’exploitation 13.464.127,03 Matières premières et consommables et autres charges externes 13.899.493,87 Matières premières et consommables 427.426,47 Autres charges externes 13.472.067,40 … |
We can observe different important points in these results:
- The language is not important, neither in the query nor in the source document (here French and English), as both of them are transformed into embeddings that are agnostic to the human language. This universal understanding is coming from the training data set that contains contents in many different languages.
- We could have contradictory information (turnover from 2020 and 2021), meaning that this outcome of this query is not enough to produce an accurate answer to the end user
Chain of actions
It is time now to think about the detailed design of the chain of actions for this chatbot.
Intent classification
The first step we want to implement is to classify the intent of the user when he is asking a question. And as we are dealing with a chat context, this intent classification cannot be only based on the current question, but must take into account the previous questions/answers.
As an example you could imagine this discussion (responses generated with OpenAI GPT-4), where the context is only defined at the first question. But the following questions are asking for extra information without repeating this context.
| 🧑💼How many Apollo missions were there in total ? |
| 🤖The Apollo program, run by NASA, the United States space agency, consisted of 17 total missions named Apollo. The list of these missions is as follows: 1. Apollo 1 (initially designated Apollo Saturn-204 and Apollo AS-204) 2. Apollo 4 (also known as Apollo AS-501) 3. Apollo 5 (also known as Apollo AS-204) 4. Apollo 6 (also known as Apollo AS-502) 5. Apollo 7 6. Apollo 8 7. Apollo 9 8. Apollo 10 9. Apollo 11 10. Apollo 12 11. Apollo 13 12. Apollo 14 13. Apollo 15 14. Apollo 16 15. Apollo 17 16. Apollo 18 (cancelled) 17. Apollo 19 (cancelled) The Apollo 1 mission ended in a tragic cabin fire during a launch rehearsal test, killing all three crew members. The actual count of the missions that officially launched, therefore, is 15. Apollo missions 18 and 19 were originally planned but were cancelled due to budgetary constraints. Missions 2 and 3 were uncrewed and renamed Apollo 4 and 5 after the Apollo 1 fire. Apollo 4, 5, and 6 were also uncrewed. The first crewed mission was Apollo 7. The Apollo program is perhaps best known for Apollo 11, the mission that first landed humans on the Moon in July 1969. |
| 🧑💼And who was the first team ? |
| 🤖The first crew assigned to the Apollo program was for the Apollo 1 mission, which tragically ended in a cabin fire during a pre-launch test. The crew members were: 1. Gus Grissom: He was one of the original Mercury 7 astronauts and had flown in space twice before Apollo 1 — once on Liberty Bell 7, a suborbital Mercury mission, and once on Gemini 3. 2. Ed White: He was the first American to walk in space during the Gemini 4 mission. 3. Roger Chaffee: Apollo 1 would have been his first spaceflight. Unfortunately, all three astronauts died in the Apollo 1 fire on January 27, 1967. This tragic event led to major design and safety changes in the subsequent Apollo spacecraft. |
| 🧑💼And the one that landed ? |
| 🤖The first Apollo mission that landed on the Moon was Apollo 11, which launched on July 16, 1969, and landed on July 20, 1969. The crew members for this mission were: 1. Neil Armstrong: He served as the mission commander and was the first person to walk on the Moon. 2. Buzz Aldrin: He was the lunar module pilot and the second person to walk on the Moon. 3. Michael Collins: He was the command module pilot. While Armstrong and Aldrin were on the lunar surface, Collins remained in lunar orbit in the Command Module. As such, he never walked on the Moon. Neil Armstrong’s first words when he stepped onto the lunar surface, “That’s one small step for [a] man, one giant leap for mankind,” are one of the most famous phrases in the history of human space exploration. |
Without any context, the last question is, of course, impossible to answer:
| 🧑💼And the one that landed ? |
| 🤖I’m sorry, but without additional context, I’m unable to determine what you’re referring to by “the one that landed”. Could you please provide more details? Are we discussing a specific event, like a spacecraft landing, a bird landing, or something else? |
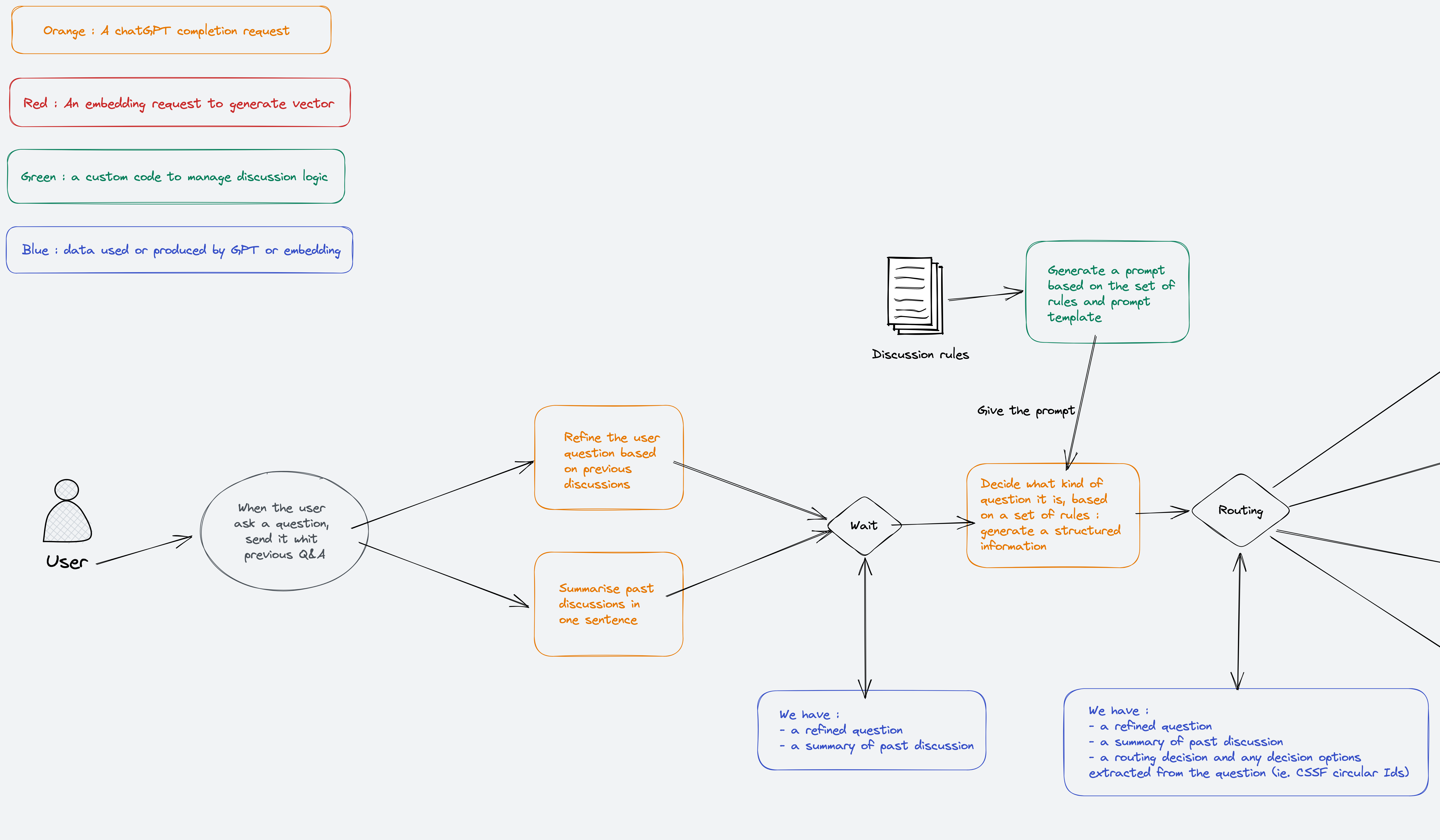
This means we need to keep the chat history, to be used when inferring the intent from a single question. The chat history can be used in a specific LLM prompt to “refine” the user question with all required context information.
Using the same example, the last question, “And the one that landed ?” must be refined to something like that : “What was the first Apollo mission that landed on the moon, and who was part of its team ?”
Also, as this intent classification must drive the next step of this chain of action, we want, as the outcome of this step, something other than a typical text answer. We want the model to give us its classification with something that can be used or detected by a regular software to know what to do next. This is something you can instruct/ask to an LLM model to generate structured data instead of generic text. This data can be then parsed by the software running the chain.
So to achieve this first step we need:
- A memory of the chat history
- A prompt to refine the user question based on the chat history
- A prompt capable of inferring the expected intent based on the refined question
In this PoC we will also add a prompt to summarise the chat history only, to be used at another step in this chain.
As we are building a software that integrates an Azure OpenAI GPT API, we can leverage on some prompt template for each specific API call.
And indeed several libraries already exist to build such applications. An important one is LangChain. LangChain is an abstraction layer on recurrent patterns and tooling for the usage of LLMs. Several concepts are also introduced in this library to build complex applications that massively rely on LLMs (i.e. Agent).
We will not discuss the details of this library here, but our PoC is using this library to leverage on its components (Models, Prompts, Indexes and Chains).
To have a memory of the chat history, several options are possible, from most simple to complex service (link history to an identity, persistence, summarisation, …). The Langchain library offers several implementations for these purposes.
As this would be an important optimization point for real-life applications, here for our purposes we will stick to something simple : the front-end application in the web browser will manage the chat history in memory.
Question refinement
To illustrate the prompt templating, here is the content of the prompt used for questions refine:
1
2
3
4
5
6
7
8
9
10
11
You are a helpful AI assistant, given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, keeping the same user language.
Your rephrasing must include any relevant history element to get a precise standalone question and not losing previous context.
Chat History:
{chat_history}
Follow Up Input: {question}
Begin!
Standalone question:
This template, rendered with chat history and current question, will allow us to call the LLM API to get a refined question.
As an example, with this prompt rendered with these inputs elements, the LLM can produce this refined question :
| Input “chat_history” |
Hi, I’m Bob, and I’m looking for information about the CSSF. Can you help me with that? |
| Hi Bob, the CSSF (Commission de Surveillance du Secteur Financier) is a public institution in Luxembourg that serves as the supervisory authority for the financial sector. Its responsibilities include ensuring financial stability, protecting financial consumers, and promoting a fair, transparent, and safe financial market. The CSSF has over 900 employees working in 19 specialised business departments and actively participates in international working groups and collaborations with other European authorities. You can find more information about the CSSF on their website: www.cssf.lu. | |
| Input “question” | And where is their office ? |
| Output | Where is the office of the CSSF (Commission de Surveillance du Secteur Financier) located? |
Classification
With the refined question, we can now ask the LLM to infer an intent related to this question.
In our use case we want to categorise 4 types of intents:
- “CSSFQuery” : Any generic question about the CSSF
- “AnyCircularQuery” : Any generic question about circulars of the CSSF
- “CircularQuery” : a question about a specific circular
- “SmallTalk” or “OT”: small talk, off-topic
These intents will allow us to choose the correct prompt for the next steps but also to scope the documents in which we want to search for information.
And to retrieve this intent as structured information, we can ask the LLM to produce information in a specific format.
To do so we use the following prompt template:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
Given the context and actions rules, choose the relevant action based on the description rules described below. And then :
- repeat the context at the end in the standalone question field
- followed by the correct action value you have selected in the action field
This should be in the following format:
Standalone question: [context here]
Action: [action name here] [if applicable, any action options here]
How to determine the correct action:
- Compare the context with the action description, and to extract any keyword or number that are relevant for the action
- If you do not know the correct action based on the context, select the default action name, with no options : "UnknownAction"
- Don't be overconfident!
Actions rules :
{rules}
And if nothing matches, use the "UnknownAction" name, without any options.
Begin !
Context:
---------
{context}
---------
Standalone question:
To keep this routing element agnostic, this template is generic and does not contain any specific rules to classify a question. That is the purpose of “rules” template input.
Here is an example of rules:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Action #1:
- action name: CircularQuery
- action description: the context is a question related to one or more specific CSSF circular (CSSF, CPDI, CODERES), and SHOULD contain an id for each of them (syntax is [number]/[number]).
- action options: extract all circulars identifiers present in the context, and add them as action name options (keep the syntax [number]/[number]). If no identifiers are found, do not add any options.
- Example with the following context: "please summarise the circulars 23/34 and 22/798 and 54/12"
Standalone question: please summarise the circulars 23/34 and 22/798 and 54/12
Action: CircularQuery 23/34 22/798 54/12
Action #2:
- action name: AnyCircularQuery
- action description: the context is a generic question about the CSSF circulars
- action options: no options for this action
- Example with the following context: "Can find the circulars related to information and communication technology (ICT) and others related to supervisory reporting requirements applicable to credit institutions"
Standalone question: Can find the circulars related to information and communication technology (ICT) and others related to supervisory reporting requirements applicable to credit institutions
Action: AnyCircularQuery
In our use case we will have 5 rules to match the expected intents.
Some example of the outcome from this template with the following inputs:
| Input context | Hello, can you please provide me with the main phone number for the CSSF? |
| Output | Hello, can you please provide me with the main phone number for the CSSF? Action: CSSFQuery |
| Input context | I would like to know more about CSSF Circular 23/34 in Luxembourg. Can you provide me with information about it? |
| Output | I would like to know more about CSSF Circular 23/34 in Luxembourg. Can you provide me with information about it? Action: CircularQuery 23/34 |
| Input context | What is the weather like today? |
| Output | What is the weather like today? Action: OT |
With this output, we can parse the generated content to continue on the next step of this chain.
Intent routing and retrieving relevant content
Here this is the most obvious step, as it is related to a more classic development:
- Parsing a text
- Call a search engine API
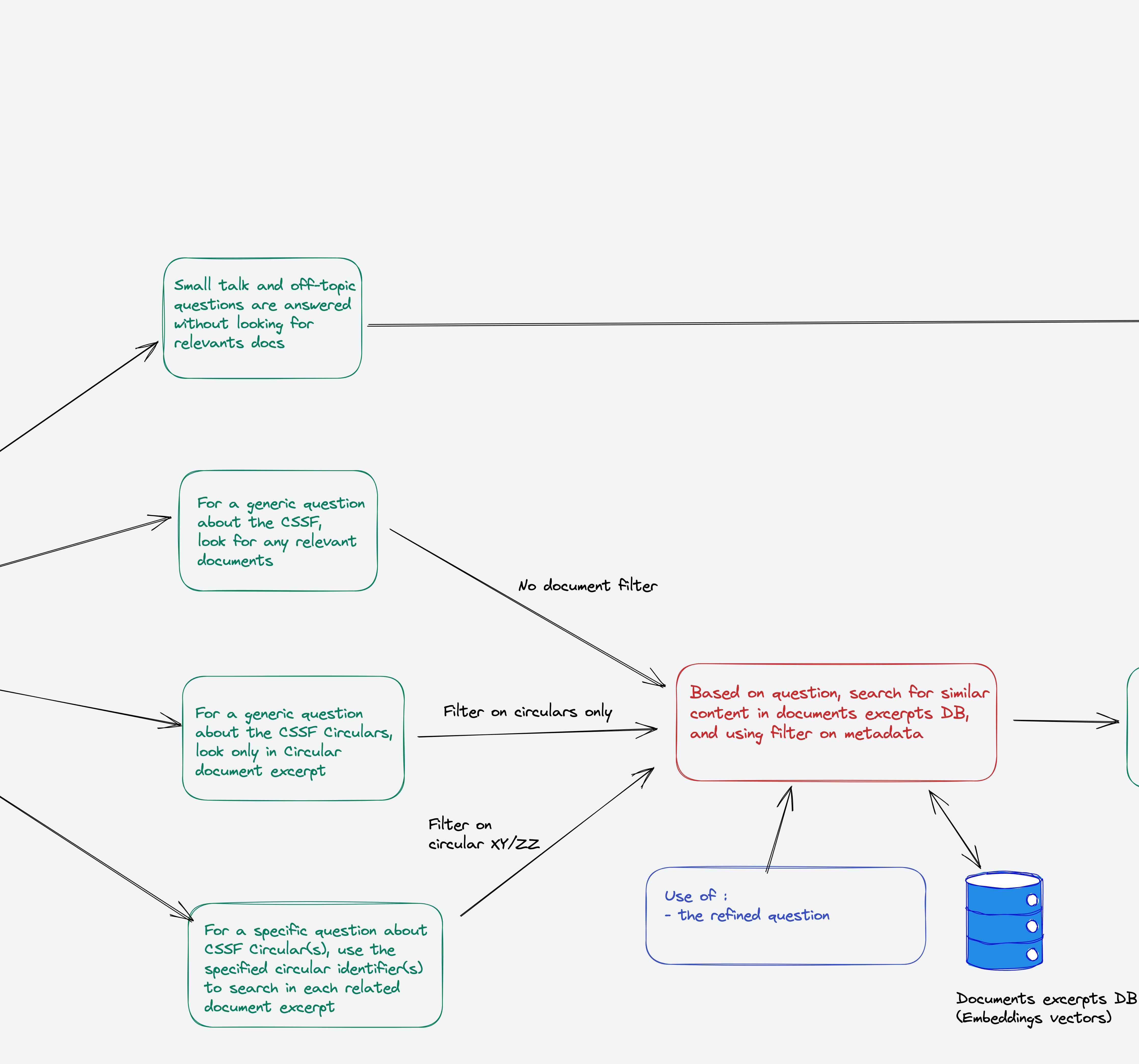
Based on the parsing we will know the intent, and so will decide what kind of search request to build:
- Small talk, off-topic or unknown : no search
- Another intent will trigger a similarity search query with the refined question. The filter applied to this query will depend on the intent:
- CSSF related: no filter
- CSSF Circulars related : filter on any circular document
- One or more Circular(s) with its id(s) : filter on the specified ids
The outcome of this step is a list of text chunks, with their related metadata.
Generating the final answer
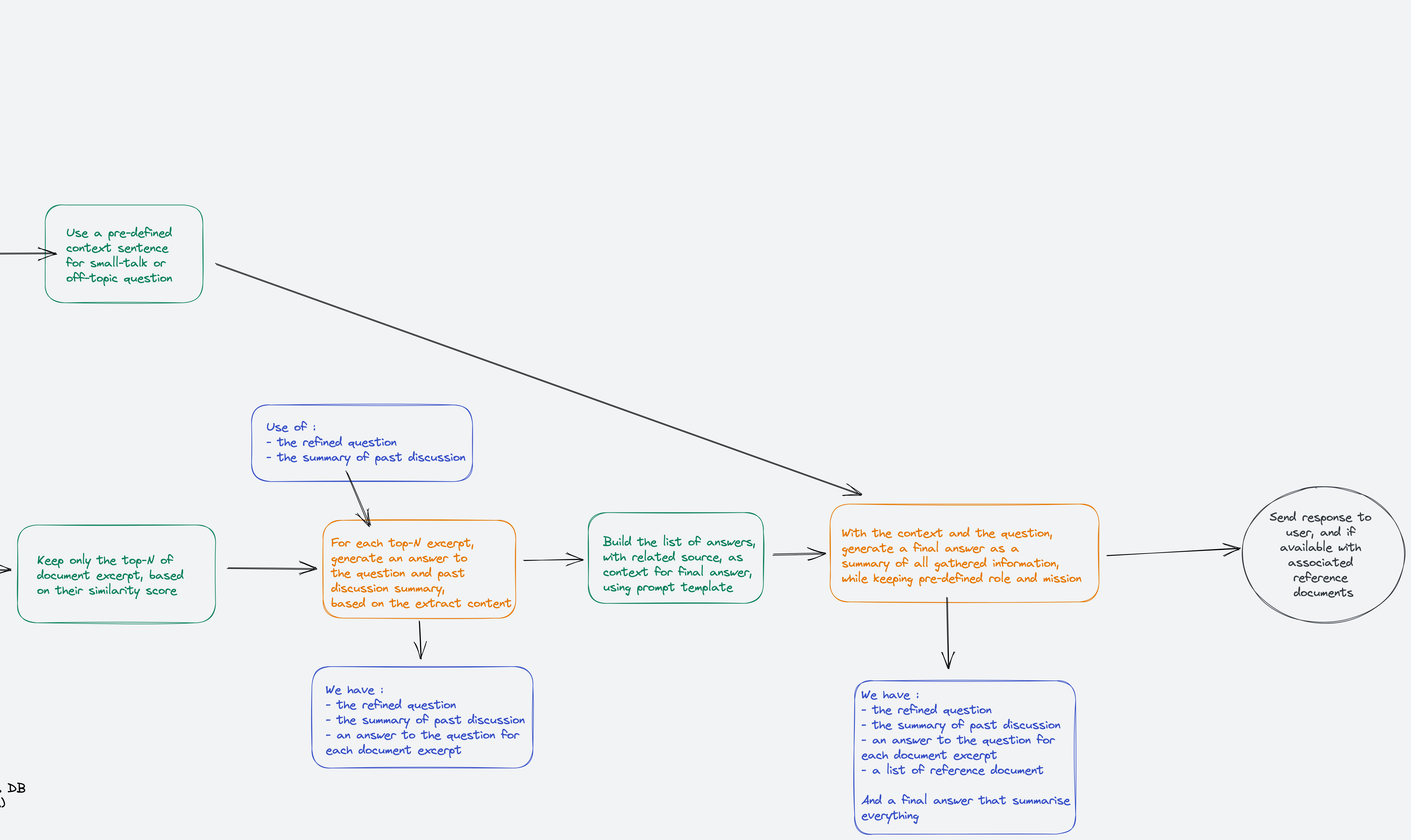
Now we have as inputs:
- The refined question
- A summary of the chat history
- A list of text chunks, with their metadata, that are the result of a similarity search
This step goal is to generate a final answer to the question, based on the text chunks.
But to use these text chunks in the final answer we need another LLM action: check if each chunk is answering the question and if so summarise.
And with these summarised possible answers, we will be able to run a final LLM action to generate the final answer.
In case of small talk, off-topic we can have a shortcut to answer politely and/or that we cannot answer this particular question.
Related documents summarisation
So we need another prompt that will be used for each text chunk.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Use the following document extract, source and discussion history to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
Begin!
document extract (source: {source}):
---------
{extract}
---------
discussion history:
---------
{history}
---------
Question: {question}
Helpful Answer:
We include in this prompt the summary of the discussion as after several tests it seems to increase the accuracy of the generated content.
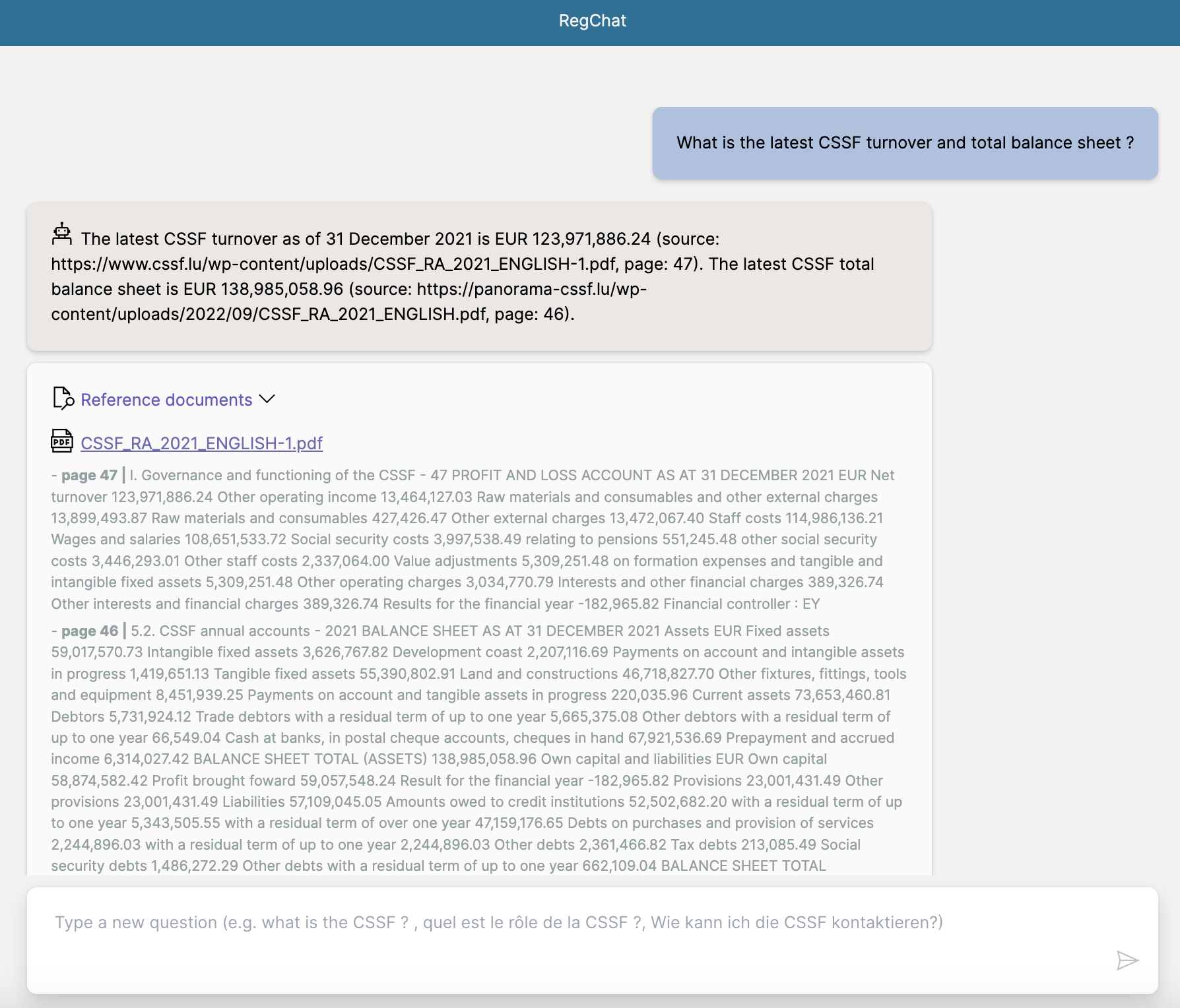
For example, with the following question “What is the latest turnover and total balance sheet for the CSSF ?”, 8 documents have been retrieved from the knowledge base and summarised. Here are some samples of the outcome from this processing:
| Generated prompt (reduced for readability) | Completion (answer) |
|---|---|
| Use the following document extract, source and discussion history to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer. Begin! document extract (source: CSSF document, available here: https://www.cssf.lu/wp-content/uploads/CSSF_RA_2021_ENGLISH-1.pdf , page: 47): ——— I. Governance and functioning of the CSSF - 47 PROFIT AND LOSS ACCOUNT AS AT 31 DECEMBER 2021 EUR Net turnover 123,971,886.24 Other operating income 13,464,127.03 Raw materials and consumables and … discussion history: ——— ——— Question: What is the latest CSSF turnover and balance ? Helpful Answer: |
The latest CSSF turnover as of 31 December 2021 is EUR 123,971,886.24. The document extract does not provide information about the balance. |
| Use the following document extract, source and discussion history to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer. Begin! document extract (source: CSSF document, available here: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2019.pdf , page: 1): ——— CSSF BALANCE SHEET AND PROFIT AND LOSS ACCOUNT AS AT 31 DECEMBER 2019 In case of discrepancies between the French and the English text, the French text shall prevail. Balance sheet and profit and loss account as at 31 December 2019 (Publication provided for in Article 22(2) of the Law of 23 December 1998 establishing a financial sector supervisory commission (“Commission de Surveillance du Secteur Financier”)); …. Cash at banks, in postal cheque accounts, cheques in hand 71,670,805.14 Prepayment and accrued income 5,382,536.78 BALANCE SHEET TOTAL (ASSETS) 146,786,589.34 ——— discussion history: ——— ——— Question: What is the latest CSSF turnover and total balance sheet ? Helpful Answer: |
The latest CSSF balance sheet total (as at 31 December 2019) is EUR 146,786,589.34. The document does not provide information on the latest CSSF turnover. |
| Use the following document extract, source and discussion history to answer the question at the end. If you don’t know the answer, just say that you don’t know, don’t try to make up an answer. Begin! document extract (source: CSSF document, available here: https://panorama-cssf.lu/wp-content/uploads/2022/09/CSSF_RA_2021_ENGLISH.pdf , page: 46): ——— 5.2. CSSF annual accounts - 2021 BALANCE SHEET AS AT 31 DECEMBER 2021 Assets EUR Fixed assets 59,017,570.73 Intangible fixed assets 3,626,767.82 Development coast 2,207,116.69 BALANCE SHEET TOTAL (ASSETS) 138,985,058.96 BALANCE SHEET TOTAL (LIABILITIES) 138,985,058.96 5. Budget and annual accounts - I. Governance and functioning of the CSSF ——— discussion history: ——— ——— Question: What is the latest CSSF turnover and total balance sheet ? Helpful Answer: |
The latest CSSF balance sheet total (assets) is EUR 138,985,058.96. The document does not provide information about the turnover. |
The summarisation has been able to extract the expected information from text chunks or to identify that a document is finally not relevant to answer the user question.
We can see that some documents are not perfectly answering the related questions, so we will use the last LLM processing to do a last classification and summarisation.
Final answer
The final step is now to combine all the information we gathered and summarise to allow the LLM to produce a human readable answer, including the source documents related to this answer.
Again we will use a prompt for that, this will include all related chunk summarisation with source information for precision.
For the same question use previously, we have the following generated prompt below
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
You are a helpful AI assistant, competent to answer any related questions to The Commission de Surveillance du Secteur Financier (CSSF),
You can also assist with practical information like contacts, organisation chart of the CSSF, physical address, phone numbers and email address.
Your knowledge is based on public CSSF documents (pdf/doc, web pages), published between January 2022 and April 2023
The CSSF description :
-------------------
The CSSF is a Luxembourg public institution, that is the supervisory authority of the Luxembourg financial sector. Its duties and its field of competence are provided for in the organic Law of 23 December 1998.
Its missions and competences are :
1) Prudential supervision
2) Supervision of markets in financial instruments, including their operators
3) Resolution
4) Control regarding the fight against money laundering and terrorist financing
5) Financial consumer protection
6) Public oversight of the audit profession
7) Sanctions
8) National, European and international cooperation
-------------------
Use the following pieces of context, that you can summarise, to answer the question at the end.
If provided, use the source information, to illustrate your answer.
But important points :
- If you don't know the answer, just say you don't know. DO NOT try to make up an answer.
- If the question is not related to the context, politely respond that you are tuned to only answer questions that are related to the context.
- If the question includes any greeting or polite word, respond accordingly.
- In your answer always keep the same language as in the question
Context:
---------
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/CSSF_RA_2021_ENGLISH-1.pdf , page: 47) : I don't have the information about the latest CSSF total balance sheet, but the latest CSSF net turnover as of 31 December 2021 is EUR 123,971,886.24.
- Possible answer from document excerpt (From CSSF document, source: https://panorama-cssf.lu/wp-content/uploads/2022/09/CSSF_RA_2021_ENGLISH.pdf , page: 47) : I don't have the information about the total balance sheet, but the latest CSSF net turnover as of 31 December 2021 is EUR 123,971,886.24.
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2020.pdf , page: 1) : I cannot provide the latest CSSF turnover as it is not mentioned in the provided document extract. However, the total balance sheet as at 31 December 2020 is EUR 139,008,821.13.
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2020.pdf , page: 3) : The latest CSSF turnover is EUR 123,732,267.90. However, the total balance sheet is not provided in the given document extract.
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2019.pdf , page: 1) : The latest CSSF balance sheet total (as at 31 December 2019) is EUR 146,786,589.34. The document does not provide information on the latest CSSF turnover.
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/Balance_sheet_CSSF_2020.pdf , page: 2) : I cannot find the latest CSSF turnover in the provided document extract. However, the total balance sheet for CSSF in 2020 is 139,008,821.13.
- Possible answer from document excerpt (From CSSF document, source: https://www.cssf.lu/wp-content/uploads/CSSF_RA_2021_ENGLISH-1.pdf , page: 46) : The latest CSSF total balance sheet is EUR 138,985,058.96. However, the document extract does not provide information about the latest CSSF turnover.
- Possible answer from document excerpt (From CSSF document, source: https://panorama-cssf.lu/wp-content/uploads/2022/09/CSSF_RA_2021_ENGLISH.pdf , page: 46) : The latest CSSF balance sheet total (assets) is EUR 138,985,058.96. The document does not provide information on the turnover.
---------
Question: What is the latest turnover and total balance sheet for the Commission de Surveillance du Secteur Financier (CSSF)?
Helpful Answer:
Before the context section we have the role and mission description of the chatbot, this part is important because it restricts the scope of answers that will be generated.
The context section contains all document (text chunks) summarisation from the previous step.
And finally we add the refined question, and we ask for an answer.
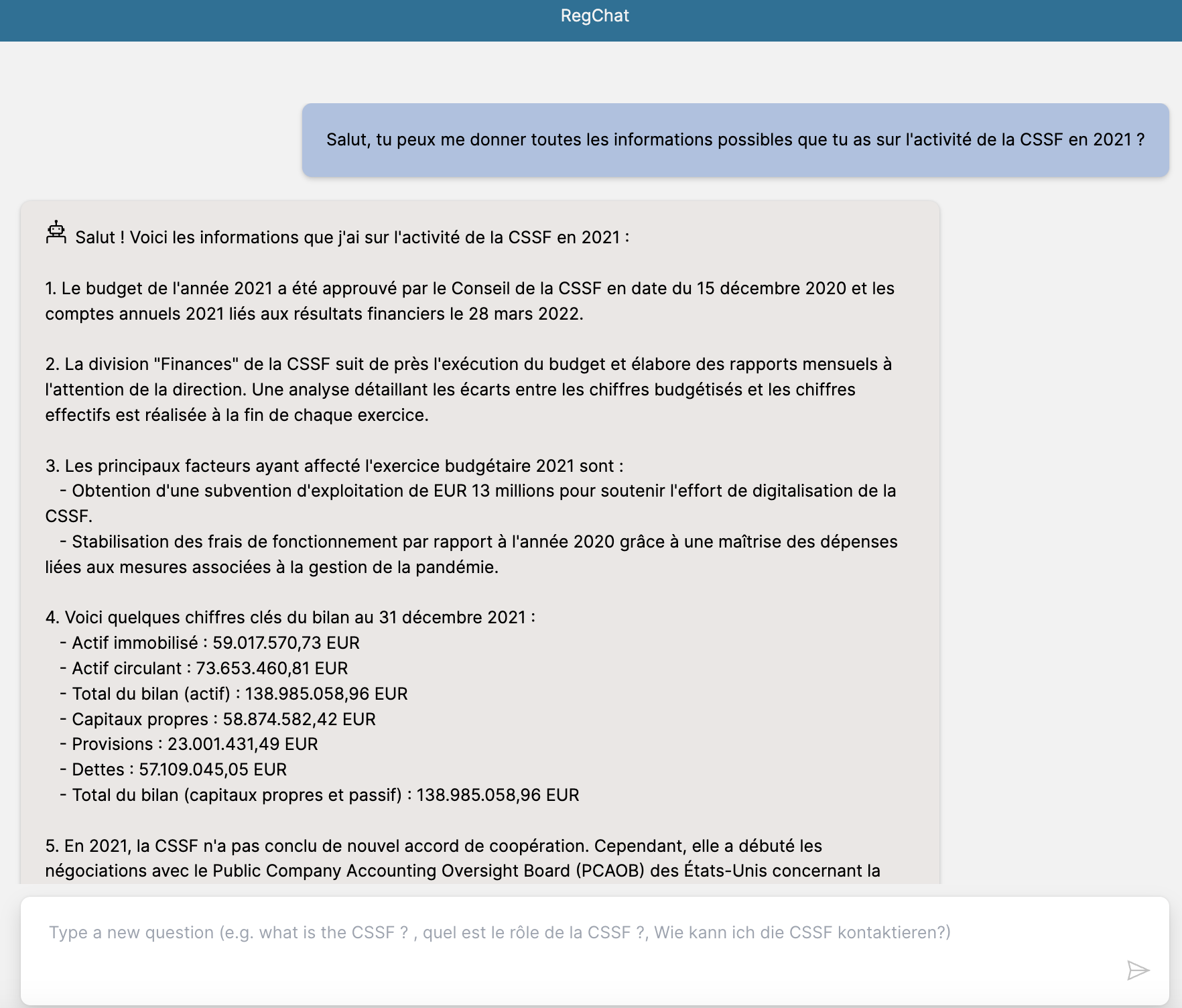
And we got an answer ! The LLM has been able to generate it by taking the expected information from the different sources, keeping what is important and removing what is not.
The turnover and the balance sheet values from 2021 are displayed (the latest activity report available from the CSSF is from 2021)
The answer could contain some document references, but in any response that was based on documents, the API also returns the list of documents thanks to the metadata. This allows the front-end application to add the “Reference documents” section below the text answer.
To compare to the public ChatGPT responses
And with the latest option “web browsing” that allows ChatGPT to browse the web, the result is even worse as the answer is totally wrong. It uses others statistics from the CSSF not related to the question.
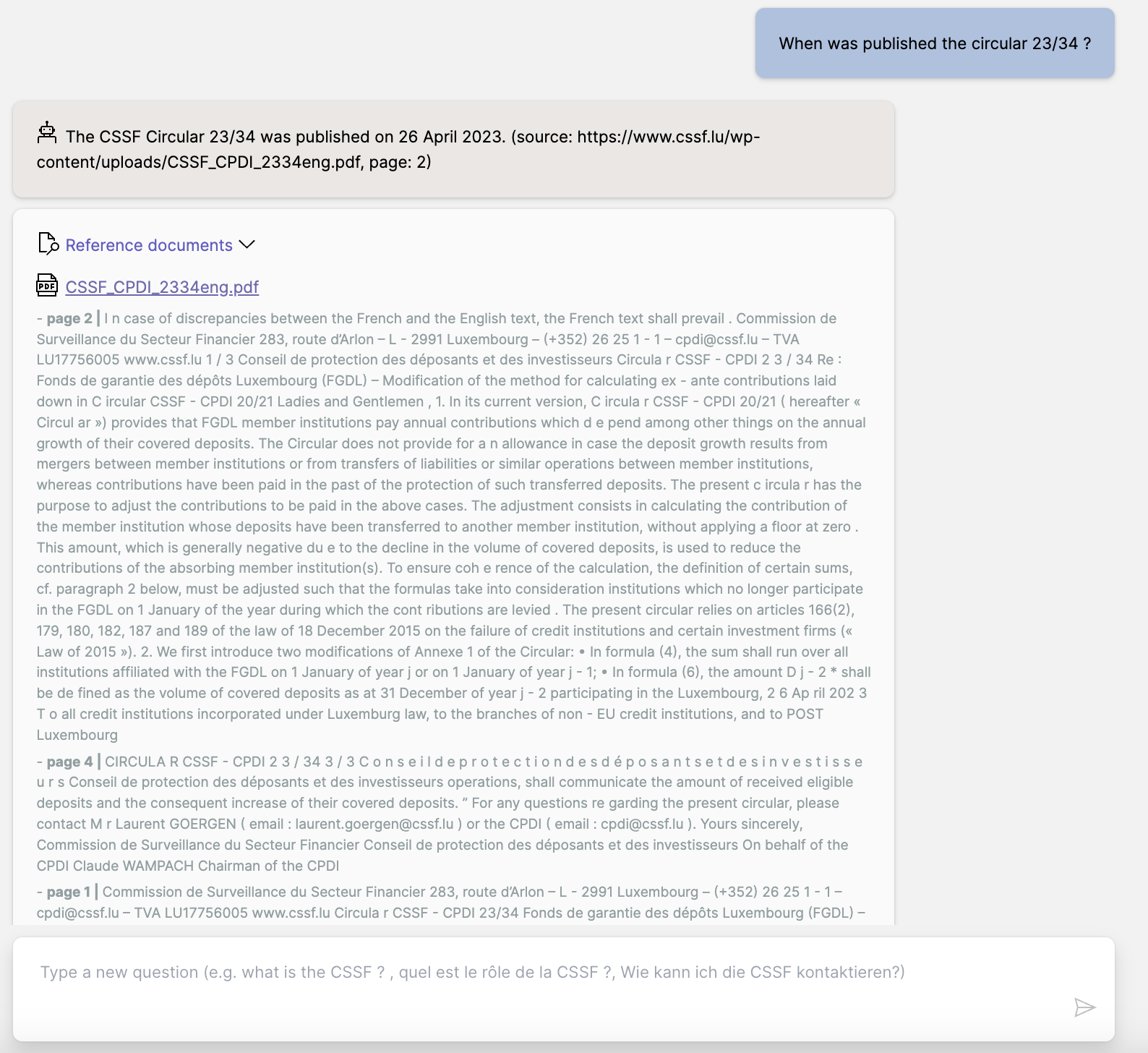
Another test with a question related to a specific circular
And the chatbot is able to speak multiple languages, here with question in French and German:
Technical architecture
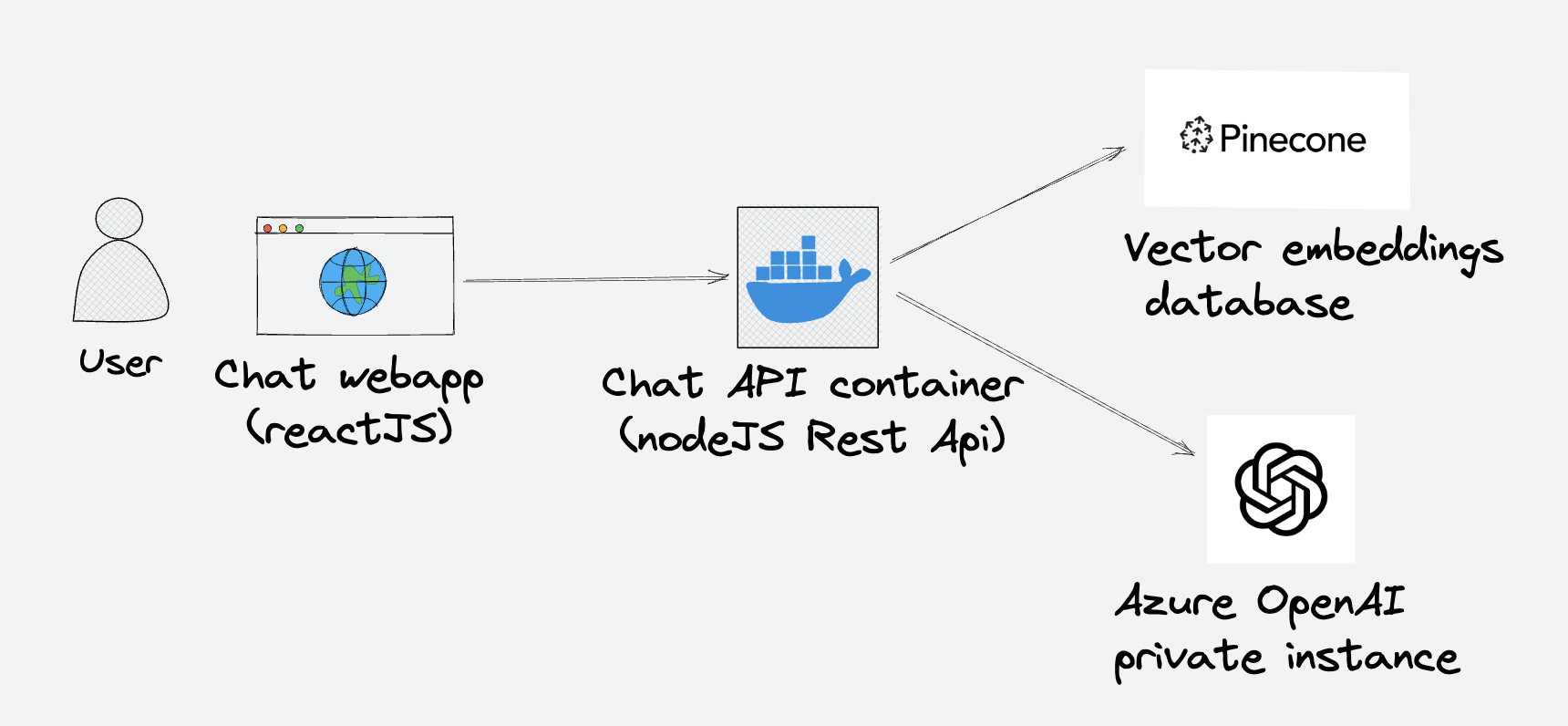
The software architecture of this chatbot is quite simple and standard.
We have a front-end application, running in a web browser that speaks with a regular REST-API, that allows to post questions, to get enriched answers (text + metadata).
The API is running the chain of actions for each request, hiding the remote call to the Azure OpenAI instance and Pinecone index.
To maintain the knowledge base, a parallel process just needs to add/update the pinecone index with new data, to keep the answers up to date.
Let’s wrap this up
Starting from scratch, with no specific knowledge on this subject, it took me about 10 days to build this chatbot, including identifying, gathering the relevant CSSF documents for this test, and setting up and deploying on Azure Cloud.
With this effort, the quality of the result is quite impressive.
But what would it be like for a real project?
Well, the first risk not to underestimate is the accuracy of the response, especially for a very specific domain where the details of the answer are crucial.
It would be incorrect to say that this type of chatbot is inadequate because it can respond inaccurately, but rather we need to measure its benefit compared to any other similar process (including human).
And with this PoC, we are already achieving a high level of accuracy with a really minimal effort.
So, to manage and mitigate this risk, I would rather say that it’s necessary to include a quality review process, with subject matter experts. This should allows to identify edge cases and adjust certain unexpected behaviours.
Also, there is still room for improvement:
- The answering processing can be slow, the chain would need to be optimised :
- testing the GPT v3.5 model, that is less accurate but really faster, for some prompts
- testing some chat history memory options, that could reduce the number of LLM calls
- Testing the model fine-tuning : it is possible to get a personalised model by doing a fine-tuning training with domain specific vocabulary, semantic or topic. This will increase the accuracy of answers when the questions are related to this domain context. But this should be seen as the latest optimization, because this task can be costly : it requires an important amount of data (let’s say at least 10k question-answer pairs) to get significant results.